But what is the Central Limit Theorem?
3.47M views6253 WordsCopy TextShare
3Blue1Brown
A visual introduction to probability's most important theorem
Help fund future projects: https://www...
Video Transcript:
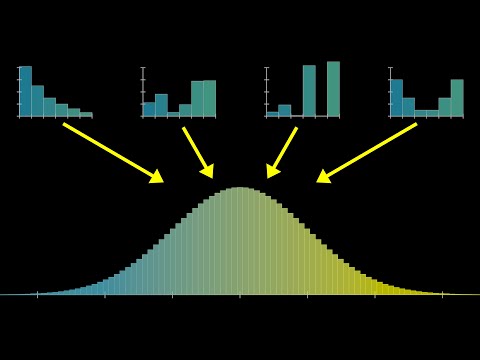
This is a Galton board. Maybe you've seen one before, it's a popular demonstration of how, even when a single event is chaotic and random, with an effectively unknowable outcome, it's still possible to make precise statements about a large number of events, namely how the relative proportions for many different outcomes are distributed. More specifically, the Galton board illustrates one of the most prominent distributions in all probability, known as the normal distribution, more colloquially known as a bell curve, and also called a Gaussian distribution.
There's a very specific function to describe this distribution, it's very pretty, we'll get into it later, but right now I just want to emphasize how the normal distribution is, as the name suggests, very common, it shows up in a lot of seemingly unrelated contexts. If you were to take a large number of people who sit in a similar demographic and plot their heights, those heights tend to follow a normal distribution. If you look at a large swath of very big natural numbers, and you ask how many distinct prime factors does each one of those numbers have, the answers will very closely track with a certain normal distribution.
Now our topic for today is one of the crown jewels in all of probability theory, it's one of the key facts that explains why this distribution is as common as it is, known as the central limit theorem. This lesson is meant to go back to the basics, giving you the fundamentals on what the central limit theorem is saying, what normal distributions are, and I want to assume minimal background. We're going to go decently deep into it, but after this I'd still like to go deeper and explain why the theorem is true, why the function underlying the normal distribution has the very specific form that it does, why that formula has a pi in it, and, most fun, why those last two facts are actually more related than a lot of traditional explanations would suggest.
That second lesson is also meant to be the follow-on to the convolutions video that I promised, so there's a lot of interrelated topics here. But right now, back to the fundamentals, I'd like to kick things off with an overly simplified model of the Galton board. In this model we will assume that each ball falls directly onto a certain central peg, and that it has a 50-50 probability of bouncing to the left or to the right, and we'll think of each of those outcomes as either adding one or subtracting one from its position.
Once one of those is chosen, we make the highly unrealistic assumption that it happens to land dead on in the middle of the peg adjacent below it, where again it'll be faced with the same 50-50 choice of bouncing to the left or to the right. For the one I'm showing on screen, there are five different rows of pegs, so our little hopping ball makes five different random choices between plus one and minus one, and we can think of its final position as basically being the sum of all of those different numbers, which in this case happens to be one, and we might label all of the different buckets with the sum that they represent, as we repeat this we're looking at different possible sums for those five random numbers. And for those of you who are inclined to complain that this is a highly unrealistic model for the true Galton board, let me emphasize the goal right now is not to accurately model physics, the goal is to give a simple example to illustrate the central limit theorem, and for that, idealized though this might be, it actually gives us a really good example.
If we let many different balls fall, making yet another unrealistic assumption that they don't influence each other, as if they're all ghosts, then the number of balls that fall into each different bucket gives us some loose sense for how likely each one of those buckets is. In this example, the numbers are simple enough that it's not too hard to explicitly calculate what the probability is for falling into each bucket. If you do want to think that through, you'll find it very reminiscent of Pascal's triangle, but the neat thing about our theorem is how far it goes beyond the simple examples.
So to start off at least, rather than making explicit calculations, let's just simulate things by running a large number of samples and letting the total number of results in each different outcome give us some sense for what that distribution looks like. As I said, the one on screen has five rows, so each sum that we're considering includes only five numbers. The basic idea of the central limit theorem is that if you increase the size of that sum, for example here would mean increasing the number of rows of pegs for each ball to bounce off, then the distribution that describes where that sum is going to fall looks more and more like a bell curve.
Here, it's actually worth taking a moment to write down that general idea. The setup is that we have a random variable, and that's basically shorthand for a random process where each outcome of that process is associated with some number. We'll call that random number x.
For example, each bounce off the peg is a random process modeled with two outcomes. Those outcomes are associated with the numbers negative one and positive one. Another example of a random variable would be rolling a die, where you have six different outcomes, each one associated with a number.
What we're doing is taking multiple different samples of that variable and adding them all together. On our Galton board, that looks like letting the ball bounce off multiple different pegs on its way down to the bottom, and in the case of a die, you might imagine rolling many different dice and adding up the results. The claim of the central limit theorem is that as you let the size of that sum get bigger and bigger, then the distribution of that sum, how likely it is to fall into different possible values, will look more and more like a bell curve.
That's it, that is the general idea. Over the course of this lesson, our job is to make that statement more quantitative. We're going to put some numbers to it, put some formulas to it, show how you can use it to make predictions.
For example, here's the kind of question I want you to be able to answer by the end of this video. Suppose you rolled a die 100 times and you added together the results. Could you find a range of values such that you're 95% sure that the sum will fall within that range?
Or maybe I should say find the smallest possible range of values such that this is true. The neat thing is you'll be able to answer this question whether it's a fair die or if it's a weighted die. Now let me say at the top that this theorem has three different assumptions that go into it, three things that have to be true before the theorem follows.
And I'm actually not going to tell you what they are until the very end of the video. Instead I want you to keep your eye out and see if you can notice and maybe predict what those three assumptions are going to be. As a next step, to better illustrate just how general this theorem is, I want to run a couple more simulations for you focused on the dice example.
Usually if you think of rolling a die you think of the six outcomes as being equally probable, but the theorem actually doesn't care about that. We could start with a weighted die, something with a non-trivial distribution across the outcomes, and the core idea still holds. For the simulation what I'll do is take some distribution like this one that is skewed towards lower values.
I'm going to take 10 distinct samples from that distribution and then I'll record the sum of that sample on the plot on the bottom. Then I'm going to do this many many different times, always with a sum of size 10, but keep track of where those sums ended up to give us a sense of the distribution. And in fact let me rescale the y direction to give us room to run an even larger number of samples.
And I'll let it go all the way up to a couple thousand, and as it does you'll notice that the shape that starts to emerge looks like a bell curve. Maybe if you squint your eyes you can see it skews a tiny bit to the left, but it's neat that something so symmetric emerged from a starting point that was so asymmetric. To better illustrate what the central limit theorem is all about, let me run four of these simulations in parallel, where on the upper left I'm doing it where we're only adding two dice at a time, on the upper right we're doing it where we're adding five dice at a time, the lower left is the one that we just saw adding 10 dice at a time, and then we'll do another one with a bigger sum, 15 at a time.
Notice how on the upper left when we're just adding two dice, the resulting distribution doesn't really look like a bell curve, it looks a lot more reminiscent of the one we started with, skewed towards the left. But as we allow for more and more dice in each sum, the resulting shape that comes up in these distributions looks more and more symmetric. It has the lump in the middle and fade towards the tail's shape of a bell curve.
And let me emphasize again, you can start with any different distribution. Here I'll run it again, but where most of the probability is tied up in the numbers 1 and 6, with very low probability for the mid values. Despite completely changing the distribution for an individual roll of the die, it's still the case that a bell curve shape will emerge as we consider the different sums.
Illustrating things with a simulation like this is very fun, and it's kind of neat to see order emerge from chaos, but it also feels a little imprecise. Like in this case, when I cut off the simulation at 3000 samples, even though it kind of looks like a bell curve, the different buckets seem pretty spiky, and you might wonder, is it supposed to look that way, or is that just an artifact of the randomness in the simulation? And if it is, how many samples do we need before we can be sure that what we're looking at is representative of the true distribution?
Instead moving forward, let's get a little more theoretical and show the precise shape these distributions will take on in the long run. The easiest case to make this calculation is if we have a uniform distribution, where each possible face of the die has an equal probability, 1 6th. For example, if you then want to know how likely different sums are for a pair of dice, it's essentially a counting game, where you count up how many distinct pairs take on the same sum, which in the diagram I've drawn, you can conveniently think about by going through all the different diagonals.
Since each such pair has an equal chance of showing up, 1 in 36, all you have to do is count the sizes of these buckets. That gives us a definitive shape for the distribution describing a sum of two dice, and if we were to play the same game with all possible triplets, the resulting distribution would look like this. Now what's more challenging, but a lot more interesting, is to ask what happens if we have a non-uniform distribution for that single die.
We actually talked all about this in the last video. You do essentially the same thing, you go through all the distinct pairs of dice which add up to the same value. It's just that instead of counting those pairs, for each pair you multiply the two probabilities of each particular face coming up, and then you add all those together.
The computation that does this for all possible sums has a fancy name, it's called a convolution, but it's essentially just the weighted version of the counting game that anyone who's played with a pair of dice already finds familiar. For our purposes in this lesson, I'll have the computer calculate all that, simply display the results for you, and invite you to observe certain patterns, but under the hood, this is what's going on. So just to be crystal clear on what's being represented here, if you imagine sampling two different values from that top distribution, the one describing a single die, and adding them together, then the second distribution I'm drawing represents how likely you are to see various different sums.
Likewise, if you imagine sampling three distinct values from that top distribution, and adding them together, the next plot represents the probabilities for various different sums in that case. So if I compute what the distributions for these sums look like for larger and larger sums, well you know what I'm going to say, it looks more and more like a bell curve. But before we get to that, I want you to make a couple more simple observations.
For example, these distributions seem to be wandering to the right, and also they seem to be getting more spread out, and a little bit more flat. You cannot describe the central limit theorem quantitatively without taking into account both of those effects, which in turn requires describing the mean and the standard deviation. Maybe you're already familiar with those, but I want to make minimal assumptions here, and it never hurts to review, so let's quickly go over both of those.
The mean of a distribution, often denoted with the Greek letter mu, is a way of capturing the center of mass for that distribution. It's calculated as the expected value of our random variable, which is a way of saying you go through all of the different possible outcomes, and you multiply the probability of that outcome times the value of the variable. If higher values are more probable, that weighted sum is going to be bigger.
If lower values are more probable, that weighted sum is going to be smaller. A little more interesting is if you want to measure how spread out this distribution is, because there's multiple different ways you might do it. One of them is called the variance.
The idea there is to look at the difference between each possible value and the mean, square that difference, and ask for its expected value. The idea is that whether your value is below or above the mean, when you square that difference, you get a positive number, and the larger the difference, the bigger that number. Squaring it like this turns out to make the math much much nicer than if we did something like an absolute value, but the downside is that it's hard to think about this as a distance in our diagram because the units are off, kind of like the units here are square units, whereas a distance in our diagram would be a kind of linear unit.
So another way to measure spread is what's called the standard deviation, which is the square root of this value. That can be interpreted much more reasonably as a distance on our diagram, and it's commonly denoted with the Greek letter sigma, so you know m for mean as for standard deviation, but both in Greek. Looking back at our sequence of distributions, let's talk about the mean and standard deviation.
If we call the mean of the initial distribution mu, which for the one illustrated happens to be 2. 24, hopefully it won't be too surprising if I tell you that the mean of the next one is 2 times mu. That is, you roll a pair of dice, you want to know the expected value of the sum, it's two times the expected value for a single die.
Similarly, the expected value for our sum of size 3 is 3 times mu, and so on and so forth. The mean just marches steadily on to the right, which is why our distributions seem to be drifting off in that direction. A little more challenging, but very important, is to describe how the standard deviation changes.
The key fact here is that if you have two different random variables, then the variance for the sum of those variables is the same as just adding together the original two variances. This is one of those facts that you can just compute when you unpack all the definitions. There are a couple nice intuitions for why it's true.
My tentative plan is to just actually make a series about probability and talk about things like intuitions underlying variance and its cousins there. But right now, the main thing I want you to highlight is how it's the variance that adds, it's not the standard deviation that adds. So, critically, if you were to take n different realizations of the same random variable and ask what the sum looks like, the variance of sum is n times the variance of your original variable, meaning the standard deviation, the square root of all this, is the square root of n times the original standard deviation.
For example, back in our sequence of distributions, if we label the standard deviation of our initial one with sigma, then the next standard deviation is going to be the square root of 2 times sigma, and after that it looks like the square root of 3 times sigma, and so on and so forth. This, like I said, is very important. It means that even though our distributions are getting spread out, they're not spreading out all that quickly, they only do so in proportion to the square root of the size of the sum.
As we prepare to make a more quantitative description of the central limit theorem, the core intuition I want you to keep in your head is that we'll basically realign all of these distributions so that their means line up together, and then rescale them so that all of the standard deviations are just going to be equal to one. And when we do that, the shape that results gets closer and closer to a certain universal shape, described with an elegant little function that we'll unpack in just a moment. And let me say one more time, the real magic here is how we could have started with any distribution, describing a single roll of the die, and if we play the same game, considering what the distributions for the many different sums look like, and we realign them so that the means line up, and we rescale them so that the standard deviations are all one, we still approach that same universal shape, which is kind of mind-boggling.
And now, my friends, is probably as good a time as any to finally get into the formula for a normal distribution. And the way I'd like to do this is to basically peel back all the layers and build it up one piece at a time. The function e to the x, or anything to the x, describes exponential growth, and if you make that exponent negative, which flips around the graph horizontally, you might think of it as describing exponential decay.
To make this decay in both directions, you could do something to make sure the exponent is always negative and growing, like taking the negative absolute value. That would give us this kind of awkward sharp point in the middle, but if instead you make that exponent the negative square of x, you get a smoother version of the same thing, which decays in both directions. This gives us the basic bell curve shape.
Now if you throw a constant in front of that x, and you scale that constant up and down, it lets you stretch and squish the graph horizontally, allowing you to describe narrow and wider bell curves. And a quick thing I'd like to point out here is that based on the rules of exponentiation, as we tweak around that constant c, you could also think about it as simply changing the base of the exponentiation. And in that sense, the number e is not really all that special for our formula.
We could replace it with any other positive constant, and you'll get the same family of curves as we tweak that constant. Make it a 2, same family of curves. Make it a 3, same family of curves.
The reason we use e is that it gives that constant a very readable meaning. Or rather, if we reconfigure things a little bit so that the exponent looks like negative 1 half times x divided by a certain constant, which we'll suggestively call sigma squared, then once we turn this into a probability distribution, that constant sigma will be the standard deviation of that distribution. And that's very nice.
But before we can interpret this as a probability distribution, we need the area under the curve to be 1. And the reason for that is how the curve is interpreted. Unlike discrete distributions, when it comes to something continuous, you don't ask about the probability of a particular point.
Instead, you ask for the probability that a value falls between two different values. And what the curve is telling you is that that probability equals the area under the curve between those two values. There's a whole other video about this, they're called probability density functions.
The main point right now is that the area under the entire curve represents the probability that something happens, that some number comes up. That should be 1, which is why we want the area under this to be 1. As it stands with the basic bell curve shape of e to the negative x squared, the area is not 1, it's actually the square root of pi.
I know, right? What is pi doing here? What does this have to do with circles?
Like I said at the start, I'd love to talk all about that in the next video. But if you can spare your excitement, for our purposes right now, all it means is that we should divide this function by the square root of pi, and it gives us the area we want. Throwing back in the constants we had earlier, the one half and the sigma, the effect there is to stretch out the graph by a factor of sigma times the square root of 2.
So we also need to divide out by that in order to make sure it has an area of 1, and combining those fractions, the factor out front looks like 1 divided by sigma times the square root of 2 pi. This, finally, is a valid probability distribution. As we tweak that value sigma, resulting in narrower and wider curves, that constant in the front always guarantees that the area equals 1.
The special case where sigma equals 1 has a specific name, we call it the standard normal distribution, which plays an especially important role for you and me in this lesson. And all possible normal distributions are not only parameterized with this value sigma, but we also subtract off another constant mu from the variable x, and this essentially just lets you slide the graph left and right so that you can prescribe the mean of this distribution. So in short, we have two parameters, one describing the mean, one describing the standard deviation, and they're all tied together in this big formula involving an e and a pi.
Now that all of that is on the table, let's look back again at the idea of starting with some random variable and asking what the distributions for sums of that variable look like. As we've already gone over, when you increase the size of that sum, the resulting distribution will shift according to a growing mean, and it slowly spreads out according to a growing standard deviation. And putting some actual formulas to it, if we know the mean of our underlying random variable, we call it mu, and we also know its standard deviation, and we call it sigma, then the mean for the sum on the bottom will be mu times the size of the sum, and the standard deviation will be sigma times the square root of that size.
So now, if we want to claim that this looks more and more like a bell curve, and a bell curve is only described by two different parameters, the mean and the standard deviation, you know what to do. You could plug those two values into the formula, and it gives you a highly explicit, albeit kind of complicated, formula for a curve that should closely fit our distribution. But there's another way we can describe it that's a little more elegant and lends itself to a very fun visual that we can build up to.
Instead of focusing on the sum of all of these random variables, let's modify this expression a little bit, where what we'll do is we'll look at the mean that we expect that sum to take, and we subtract it off so that our new expression has a mean of zero, and then we're going to look at the standard deviation we expect of our sum, and divide out by that, which basically just rescales the units so that the standard deviation of our expression will equal one. This might seem like a more complicated expression, but it actually has a highly readable meaning. It's essentially saying how many standard deviations away from the mean is this sum?
For example, this bar here corresponds to a certain value that you might find when you roll 10 dice and you add them all up, and its position a little above negative one is telling you that that value is a little bit less than one standard deviation lower than the mean. Also, by the way, in anticipation for the animation I'm trying to build to here, the way I'm representing things on that lower plot is that the area of each one of these bars is telling us the probability of the corresponding value rather than the height. You might think of the y-axis as representing not probability but a kind of probability density.
The reason for this is to set the stage so that it aligns with the way we interpret continuous distributions, where the probability of falling between a range of values is equal to an area under a curve between those values. In particular, the area of all the bars together is going to be one. Now, with all of that in place, let's have a little fun.
Let me start by rolling things back so that the distribution on the bottom represents a relatively small sum, like adding together only three such random variables. Notice what happens as I change the distribution we start with. As it changes, the distribution on the bottom completely changes its shape.
It's very dependent on what we started with. If we let the size of our sum get a little bit bigger, say going up to 10, and as I change the distribution for x, it largely stays looking like a bell curve, but I can find some distributions that get it to change shape. For example, the really lopsided one where almost all the probability is in the numbers 1 or 6 results in this kind of spiky bell curve.
And if you'll recall, earlier on I actually showed this in the form of a simulation. Though if you were wondering whether that spikiness was an artifact of the randomness or reflected the true distribution, turns out it reflects the true distribution. In this case, 10 is not a large enough sum for the central limit theorem to kick in.
But if instead I let that sum grow and I consider adding 50 different values, which is actually not that big, then no matter how I change the distribution for our underlying random variable, it has essentially no effect on the shape of the plot on the bottom. No matter where we start, all of the information and nuance for the distribution of x gets washed away, and we tend towards this single universal shape described by a very elegant function for the standard normal distribution, 1 over square root of 2 pi times e to the negative x squared over 2. This, this right here is what the central limit theorem is all about.
Almost nothing you can do to this initial distribution changes the shape we tend towards. Now, the more theoretically minded among you might still be wondering what is the actual theorem, like what's the mathematical statement that could be proved or disproved that we're claiming here. If you want a nice formal statement, here's how it might go.
Consider this value where we're summing up n different instantiations of our variable, but tweaked and tuned so that its mean and standard deviation are 1, again meaning you can read it as asking how many standard deviations away from the mean is the sum. Then the actual rigorous no-jokes-this-time statement of the central limit theorem is that if you consider the probability that this value falls between two given real numbers, a and b, and you consider the limit of that probability as the size of your sum goes to infinity, then that limit is equal to a certain integral, which basically describes the area under a standard normal distribution between those two values. Again, there are three underlying assumptions that I have yet to tell you, but other than those, in all of its gory detail, this right here is the central limit theorem.
All of that is a bit theoretical, so it might be helpful to bring things back down to earth and turn back to the concrete example that I mentioned at the start, where you imagine rolling a die 100 times, and let's assume it's a fair die for this example, and you add together the results. The challenge for you is to find a range of values such that you're 95% sure that the sum will fall within this range. For questions like this, there's a handy rule of thumb about normal distributions, which is that about 68% of your values are going to fall within one standard deviation of the mean, 95% of your values, the thing we care about, fall within two standard deviations of the mean, and a whopping 99.
7% of your values will fall within three standard deviations of the mean. It's a rule of thumb that's commonly memorized by people who do a lot of probability and stats. Naturally, this gives us what we need for our example, and let me go ahead and draw out what this would look like, where I'll show the distribution for a fair die up at the top, and the distribution for a sum of 100 such dice on the bottom, which by now as you know looks like a certain normal distribution.
Step 1 with a problem like this is to find the mean of your initial distribution, which in this case will look like 1 6th times 1 plus 1 6th times 2 on and on and on, and works out to be 3. 5. We also need the standard deviation, which requires calculating the variance, which as you know involves adding all the squares of the differences between the values and the means, and it works out to be 2.
92, square root of that comes out to be 1. 71. Those are the only two numbers we need, and I will invite you again to reflect on how magical it is that those are the only two numbers you need to completely understand the bottom distribution.
Its mean will be 100 times mu, which is 350, and its standard deviation will be the square root of 100 times sigma, so 10 times sigma, 17. 1. Remembering our handy rule of thumb, we're looking for values two standard deviations away from the mean, and when you subtract 2 sigma from mean, you end up with about 316, and when you add 2 sigma you end up with 384.
There you go, that gives us the answer. Okay, I promised to wrap things up shortly, but while we're on this example, there's one more question that's worth your time to ponder. Instead of just asking about the sum of 100 die rolls, let's say I had you divide that number by 100, which basically means all the numbers in our diagram in the bottom get divided by 100.
Take a moment to interpret what this all would be saying then. The expression essentially tells you the empirical average for 100 different die rolls, and that interval we found is now telling you what range you are expecting to see for that empirical average. In other words, you might expect it to be around 3.
5, that's the expected value for a die roll, but what's much less obvious and what the central limit theorem lets you compute is how close to that expected value you'll reasonably find yourself. In particular, it's worth your time to take a moment mulling over what the standard deviation for this empirical average is, and what happens to it as you look at a bigger and bigger sample of die rolls. Lastly, but probably most importantly, let's talk about the assumptions that go into this theorem.
The first one is that all of these variables that we're adding up are independent from each other. The outcome of one process doesn't influence the outcome of any other process. The second is that all of these variables are drawn from the same distribution.
Both of these have been implicitly assumed with our dice example. We've been treating the outcome of each die roll as independent from the outcome of all the others, and we're assuming that each die follows the same distribution. Sometimes in the literature you'll see these two assumptions lumped together under the initials IID for independent and identically distributed.
One situation where these assumptions are decidedly not true would be the Galton board. I mean, think about it. Is it the case that the way a ball bounces off of one of the pegs is independent from how it's going to bounce off the next peg?
Absolutely not. Depending on the last bounce, it's coming in with a completely different trajectory. And is it the case that the distribution of possible outcomes off of each peg are the same for each peg that it hits?
Again, almost certainly not. Maybe it hits one peg glancing to the left, meaning the outcomes are hugely skewed in that direction, and then hits the next one glancing to the right. When I made all those simplifying assumptions in the opening example, it wasn't just to make this easier to think about.
It's also that those assumptions were necessary for this to actually be an example of the central limit theorem. Nevertheless, it seems to be true that for the real Galton board, despite violating both of these, a normal distribution does kind of come about? Part of the reason might be that there are generalizations of the theorem beyond the scope of this video that relax these assumptions, especially the second one.
But I do want to caution you against the fact that many times people seem to assume that a variable is normally distributed, even when there's no actual justification to do so. The third assumption is actually fairly subtle. It's that the variance we've been computing for these variables is finite.
This was never an issue for the dice example because there were only six possible outcomes. But in certain situations where you have an infinite set of outcomes, when you go to compute the variance, the sum ends up diverging off to infinity. These can be perfectly valid probability distributions, and they do come up in practice.
But in those situations, as you consider adding many different instantiations of that variable and letting that sum approach infinity, even if the first two assumptions hold, it is very much a possibility that the thing you tend towards is not actually a normal distribution. If you've understood everything up to this point, you now have a very strong foundation in what the central limit theorem is all about. And next up, I'd like to explain why it is that this particular function is the thing that we tend towards, and why it has a pi in it, what it has to do with circles.
Thank you.
Related Videos

24:46
Why π is in the normal distribution (beyon...
3Blue1Brown
1,597,932 views
27:25
Convolutions | Why X+Y in probability is a...
3Blue1Brown
677,064 views

23:34
Why Democracy Is Mathematically Impossible
Veritasium
3,762,902 views

26:24
The Key Equation Behind Probability
Artem Kirsanov
78,065 views

11:14
The Man Who Solved the World’s Most Famous...
Newsthink
859,075 views

21:44
The weirdest paradox in statistics (and ma...
Mathemaniac
1,060,553 views
![The most beautiful equation in math, explained visually [Euler’s Formula]](https://img.youtube.com/vi/f8CXG7dS-D0/mqdefault.jpg)
26:57
The most beautiful equation in math, expla...
Welch Labs
682,864 views

23:01
But what is a convolution?
3Blue1Brown
2,642,056 views

10:51
The Galton Board
D!NG
2,581,261 views

17:26
Researchers thought this was a bug (Borwei...
3Blue1Brown
3,544,769 views

21:36
Fractals are typically not self-similar
3Blue1Brown
4,009,111 views

22:56
Visualizing 4D Pt.1
HyperCubist Math
465,315 views

42:09
Teach me STATISTICS in half an hour! Serio...
zedstatistics
2,772,628 views

33:06
Mathematicians Use Numbers Differently Fro...
Veritasium
6,501,952 views

15:11
Bayes theorem, the geometry of changing be...
3Blue1Brown
4,384,552 views

27:07
How (and why) to raise e to the power of a...
3Blue1Brown
2,840,926 views

7:35
The Central Limit Theorem, Clearly Explain...
StatQuest with Josh Starmer
768,596 views

20:52
I misunderstood Schrödinger's cat for year...
FloatHeadPhysics
369,977 views

31:51
Visualizing quaternions (4d numbers) with ...
3Blue1Brown
4,684,885 views

27:14
What is Jacobian? | The right way of think...
Mathemaniac
1,848,887 views