Developing an LLM: Building, Training, Finetuning
37.79k views9947 WordsCopy TextShare
Sebastian Raschka
REFERENCES:
1. Build an LLM from Scratch book: https://mng.bz/M96o
2. Build an LLM from Scratch repo...
Video Transcript:
yeah hi everyone so today I want to talk about developing an llm a large language model and in particular I want to talk about the three stages building training and fine-tuning large language models so but before we begin with the building aspect of large language models I wanted to briefly go over the different use cases or the different ways we are using large language models so the yeah maybe most popular way to use large language models these days is via a public or proprietary service like a public API or proprietary um you know like API
so for example chat GPT or um yeah perplexity Gemini and um others so we would basically go to website ask um or give the LM instruction or ask at a question and then it uh yeah Returns the answer so this would be one way of using a lot language model the other one is yeah nowaday is also very popular thanks to open source and open weights so that's running a custom large language model locally so here's an example running a llama 3 Model 8 billion Lama 3 model and yeah I can also similarly give it
my query and my terminal here and yeah interact with the llm yeah let's say locally and here I'm using a particular tool called libt that I help um developing so another way then is also deploying a custom large language model for example um yeah deploying it on an external server or web service and then we can also use um the llm Via an API and this is um especially useful or interesting if we are developing products so going back one slide so here it's really more like for me as a customer I can or as
a user I can run my own LM and use it and this one is for example an option where I can still run my llm locally or on server but the difference is that we um have an API endpoint that we can then use for example in an application it could be uh user interface like cat GPT like the UI but it could also be uh iPhone app or something like that so I would say yeah these are the three common ways of how we are using llms like the typical ways to interact with them
um they are all different use cases and they also have different tradeoffs personally I use all three of them so for different you know for different tasks or for different goals I use different approaches and there is no right or wrong and there is no better or worse they all have different kinds of tradeoffs so um but today the talk is not about yeah the different trade-offs of these usages I wanted to yeah pull the curtain back a bit uh and talk about what goes into developing llms that we can then run like I've shown
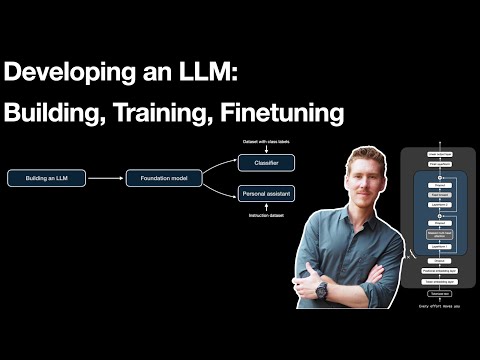
you before so what goes into creating that llm in the first place in particular I want to talk about these different stages of developing an llm so this involves building the llm itself so here we have to prepare the data sampling the data set and so forth we have to do some coding implement this attention mechanism that is at the heart of the llm it's essentially the motor if you will of the llm and then of course also coding the whole architecture around it so if the attention mechanism is let's say the motor of a
car the LM architecture would be basically everything surrounding that motor like connecting the wheels putting driver seats in a steering wheel and everything else um the second stage then is the pre-training stage um so this would be essentially taking an large length Model A large language model architecture and then training it on a data set for that we have to implement the training Loop the model evaluation and um usually we also want a mechanism to save and load um pre-trained weights so that we can use the large language model later because usually this um stage
is what forms a so-called Foundation model so it's usually not our end product it's like an intermediate um yeah I would say product in in this pipeline but in general it's more like the foundation or the base model that we use then for fine-tuning and so fine-tuning um yeah that can be different things so we could for example fine tune a model to do classification you know like text categorization um yeah identifying spam email and these types of things but we can also yeah train a personal assistant a chatbot for that we can use an
instruction data set for example so um by the way all the figures I'm showing you are for my book uh build a large language model from scratch so um I made all these figures for my book so I'm just reusing them here or not all of them but many are from the book um and in the book is also more code if you actually want to build it because this talk is only conceptual so here I'm going over the concepts and if you're interested in coding something like this yourself um you have more details in
the book and also I have a GitHub repository with all the code examples so starting with stage one the building here so here we will be putting together the llm architecture itself but um even taking a step back before we implement the architecture we will take a look at the data set how the data set um looks like or how a data set looks like and then how we feed that data set into the large language model and this is actually um in my opinion a good way of yeah of understanding how an llm works
because understanding how an llm Works kind of requires to understand what it works with what does the data set look like so if we understand um how we feed the data into the llm we are already closer to understanding yeah how the mechanism the llm architecture works and so forth um so yeah this is the reason why at the very left here we are starting with the data set preparation and sampling um explaining it um before we actually do the pre-training because I do think it helps um understanding a bit um how an llm works
so um yeah LM is essentially you can think of it as a deep neural network if you have done deep learning before so especially I think if you're watching this video you have maybe seen some of my other videos on YouTube so you probably um have some background in machine learning and deep learning so for now I would say um the simplest way to think of a large language model is really to think of it as a large deep neur Network and this deep new network is yeah uh model that is trained to predict the
next word in the text so that's the first stage when we do the pre-training we train the model to predict just the next word in a sentence or in a text and yeah we call that also sometimes the next word prediction task but um essentially it's the next token prediction task and I will Al explain in a bit what the token is so just to show you what that looks like so if we have an example text here at the top um the example text is llms learn to predict one word at a time so
I want to train let's say the model on this text of course the real world data set is much much larger it's billions of words but just you know to give a example that fits into this um slide so on the left hand side if we have a sentence like that we take to start with the left word um let's say llms here that is what the llm receives as an input then the learn is the Target that it should predict so that's the next word and everything right from the target here on the right
hand side is For Now hidden from the llm so we are just feeding at llms the word llms and then um it's supposed to predict the next word learn in this case so um here let's say are two training input examples so the first sample is llms the model um generates or supposed to generate learn the second sample is lm's learn and then the next word it should predict is to and then we continue on to construct the data set such that we give the llm learning tasks where one word is missing and it's supposed
to generate this next word we I will explain later um a bit more let's say how how that works how the pre-training or let's say the training function works I will say a few more words about that but in general that's yeah how we would prepare a data set for pre-training now in practice this would be quite inefficient to feed it just one you know sentence or um text at a time so in practice what we do is we do a batching like we do in deep learning in general so what that means is we
are putting multiple training inputs together into a batch and usually batches have to have the same length because they are implemented as um tensors so where we you can think of it almost like yeah as a matrix and um so we have to have the same number of elements in the columns so usually yeah we prepare the data set like that where we take um fixed size inputs sliding it over the text here to create such a batch and we would do that for the whole data set then of course I'm only showing you um
is it one two three four um four words in one row but in reality these are much larger so usually we are working with input length of at least um I would say uh 256 for a very small model 1024 or even larger for pre-training so we usually uh yeah give it bigger inputs but again this is a small text example just to make it fit onto this um slide here so the question now is if we um yeah if we just predict one word at a time so if we train the llm so that
it can only predict the next word how can an LM actually then generate a multi-word output so for example in the case if you used a Chet GPD before it can generate this whole output um all at once how does that work so this is usually um still a one-word prediction task per iteration so here for example if I have an input and that is called or the sentence no let's say the text is this and um I feed it to the llm the output here would be this is so it's still um generating only
the next word but what we do then is we pass this um output here so I hope you can see the mous uh you can pass this output here back into the llm and so the context here is now one word more than before it passes again through the llm and now it's this is n so if we added another word and then again we take this output feed it back to the llm and then yeah uh we have one word more and we keep on doing this until um either we generate a so-called end
of text token which is a special token that will stop the generation process or we reach a let's say um system or user specified number of tokens and uh if you next time if you use chat GPT you have to maybe uh if you let's say pay attention if you put in some input text some longer that requires a longer answer you will see it's also generating one word at a time in this output it's like this um visual cue almost where it doesn't generate all the output all at once you don't see the block
of text appearing all at once it's really um showing you also this um word by word uh generation which is I feel like a small gimmick in the UI but it also kind of highlights in a way how llms generate texts um yeah so um this is how we get from the let's say next word prediction task to actually generating outputs so there's one more thing I mentioned earlier um actually we are not generating one word at a time it's uh called a token actually so there's a small distinction between words and tokens so if
we have some input text here what happens internally is that this um input text gets tokenized so it's basically uh in this very simple example tokenized based on white spaces but that's just a very simple example and um usually it's a bit more complic at it but the general concept is that we break down the sentence into individual word tokens or punctuation in this case so we have from this input text 1 two 3 four five tokens and from that we then um get token IDs so um this is I'm not showing in this presentation
because it would be maybe more like a three-hour presentation rather than a um 45 minute presentation but um so there's usually a vocabulary that we built based on all the unique words in the training data set and based on that vocabulary um yeah we we assign in these token indes so words you can see with um smaller um letters sorry with the letters that come earli in the alphabet um have smaller numbers and this is a larger number you or you know like if it's alphabetically um punctuation maybe and numbers come first and these smaller
words or tokens with a at the beginning and then alphabetically you can see they get larger and there is actually um also a more sophisticated process of play um I mean depends on what llm you are working with but for example GPT originally I think they still do uh use a modified version of that it's called a bpe tokenizer I think it stands for bite pair encoding if I recall correctly um and there are variations of that like sentence piece for llama and so they can also deal with unknown words so if you have an
unknown word so like some word or two words I made up here they would then be sub tokenized so you can see um it breaks it down like this so what I'm trying to say is even if your words didn't appear in the training set when you build this bpe tokenizer um or if you use an existing LBP tokenizer that has not been seeing such a word it would still be able to give you tokens it's just giving you more tokens now so it's not one token per word it's like um for this word it's
like 1 2 3 four four tokens because it doesn't recognize the word so it's breaking it down into individual letters here in this case and this is why to some extent um llms also work with unknown words um they wouldn't crash or something but it's yeah it's just inefficient basically so you want to essentially um try to represent all the words in in the vocabulary if you can but of course if a user comes up with a new word or something it shouldn't fail or crash okay um so I talked about simple data sets in
reality um there are so data sets that are used for training LMS are much larger than the small Snippets I've shown you so back then for example when um gbd3 was trained it was trained on yeah almost 5 billion 500 billion tokens so it's half a trillion tokens this is uh back in 2020 long time ago and but what's nice um about this is also back then researchers um still showed or roughly showed what they used for training so they shared a bit of the details that went into training that model so for example they
talk a bit about um in the paper what these data sets are for example Wikipedia data sets some book data sets uh website crawl data set and so forth and uh yeah nowadays it's less common nowadays it's really um they maybe tell you how big the data set was but they don't share any details anymore um so uh but another yeah example from uh back then I think this should actually be 2023 I have to correct this was Lama one by meta Ai and here um yeah they trained so my main point was essentially training
sets are getting larger so we are going from 500 billion to 1.4 trillion it's um three times larger now um even larger when we go to Lama 2 so it's 2 trillion and then Lama 3 it's 15 trillion but going back steps so here we can still see what went into that data so we have GitHub now um archive papers um here um stack Overflow and stack exchange data and so forth um newer models they don't actually reveal that information anymore it just says um a new mix of data from publicly available sources and for
Lama 3 it's um 15 trilon tokens that were all collected from publicly available sources um it's a bit unfortunate if you um you know as a researcher want to know a bit more um how the data set look like um for example if you are trying to put down or together your own um data set um but I think this is really because yeah some companies have been sued um by training on data that was protected so basically we actually shouldn't go out and just train LMS on publicly available data because publicly available doesn't mean
we are supposed or allowed to use that data and so I guess by not saying what the data set is here um researchers try or companies try to avoid um lawsuits so um yeah Al I should say my book um I'm only training um the llm on example data that is in the public domain where um this is from data that is not copyrighted so I'm also making sure of that because I uh yeah I think um we should respect that if data is yeah let's say not designated for training we probably shouldn't use that
um anyways U so here I just wanted to show you or highlight the sizes of the different data sets that have been used to to train LM so the trend goes towards um yeah more data according to the scaling lws for a certain size we still haven't saturated the performance of LM so with more data we can still squeeze out more performance the only um recent paper I would say that I I I'm aware of or model that I'm aware of that went into a bit of a different trend is um the fi3 model by
meta uh sorry by by Microsoft I mean so the F model by Microsoft um they focused more on developing smaller models with um smaller amounts of data so they um are argue here um actually even using less data that would be um considered optimal would actually be beneficial to the llm because you leave some let's say capacity for learning certain behaviors or reasoning for example so here for example they say they don't ex they don't include the result of a game in Premier League in a particular day um because this is I mean this is
correct information but it's not necessarily that useful um to memorize you know like I wouldn't say it's trivial for Premier League fans uh no offense here I I watch also sometimes Premier League games uh Liverpool so I'm a Liverpool fan fan in particular but in uh in general I would say depends on what you want to build here um so unless you are trying to build a sports knowledge base or something like that it's maybe not necessary to feed all that um yeah data about all the games into the llm because then you yeah you
you trade it off with um other things or qualities so here they argue um that they leave more capacity for reasoning by not training the model on too much data for example I mean this is a hypothesis um it's yeah a valid argument I would say but of course also as others have shown more data can be better so it's you know it's something I think that we will see um trickling out in the upcoming months or years when we see some other or additional architectures um doing some investigation here because um these are both
very recent papers um or Lama 3 is not even published as a paper it's just released so we don't have really that much information about these yet F just came out a few weeks ago so in that case um yeah we need to really see more research to say whether this is uh actual thing here with a capacity okay moving on though um so we talked about the data we understand a bit now how an llm receives data uh that it learns to predict the next word but um yeah what goes into um developing an
LM that can read this data what is um let's say the architecture what do the architectures look like here so let's talk about the architecture and then I will briefly revisit um the pre-training and then we will talk about model evaluation and the fine-tuning stages so because I fear this talk might be a very long talk that might go many many hours I'm not going into too much detail of these individual components but I'm just showing you um yeah how how the original and gpt2 and three models look like so this is the basic architecture
that was used to um develop the GPT models we don't know exactly how GPT 4 looks like um so there's no paper about that but for the first um three GPD models is um yeah this type of architecture here and um there are certain components I will maybe say something about that later that are not used anymore but in in general it's this um the same cookie cutter template that is also used for other llms so in particular there's this masked multi-ad attention module um there are feet forward layers um it's essentially two linear layers
usually with uh nonlinear activation um the silu or silu activation they have um it depends also how you structure it but it has it can have three linear layers depending on how you write the code um yeah positional embedding layer it's usually for the input token embedding layer and yeah this is a layer Norm here some architectures use RMS Norm but this is the overall architecture what's interesting is um here in blue that is the so-called Transformer block and this is an element that is repeated a number of times um and that really depends on
on the size of the llm but usually I would say you repeat that at least 12 to 32 64 times depending on the size of the llm you actually have some numbers so um for the small so here maybe to back up a bit so here are different sizes of the gbt2 model um from 124 million parameters to 1.5 billion or, 500 million and the difference between these architectures is really I would say minor it's really just the number of times you repeat this um Transformer block from 12 to 48 and um also the number
of heads in the multi-ad attention mechanism it's essentially if you are familiar I should maybe make a lecture on that too but if you're familiar with um convolution networks if you think about the channels in a conv convolutional layer you can think um of the heads and multier tension as an equivalent so it's basically stacking like stacking um channels in a convolution network here you stacking these multi-ad attention heads and really the difference between the small model and the large model is just the number of times you repeat this like how many how how deep
your stack is but it's the same element so so the key idea here is really that we are reusing elements and we just um you know duplicating these elements to make the models larger another small difference here is the embedding dimension for example the smallest one has 768 the larger one has um 1,600 I think nowadays um it's also common to go 4,000 to 8,000 for example so um just to take an example from uh llama so the meta 2 sorry The Meta AI Lama 2 model the 7 billion version so what they done what
they've done here is they replaced layer Norm with RMS norm and RMS s Norm a root mean Square Norm is basically what most I would say most modern architectures use um it's basically an normalization layer similar if you're familiar with batch Norm it's kind of like batch Norm but it works better for um multi-gpu training essentially because uh you can have so yeah you don't have to gather over the batch size basically so it's bad patch size independent is what I'm trying to say um yeah so you have the CEO instead of G activate here
you repeat it 32 times in the case of 7B model you don't have Dropout and yeah for the embedding layers um usually we use um for POS for the positional embedding we use uh rope I think it stands for rotational positional embeddings so the first GPT model has absolute um an absolute position embedding and yeah newer newer models they use a relative positional embedding and the um the size is a bit bigger before we had 1,28 tokens now we have 4,000 it's four times yeah three times large basically a bit more than three times but
yeah um yeah and this is essentially I would say the main difference um the takeaway here is really that most LMS are still very similar to each other um they are very small I would say changes in some llms like these and that's also why in L GPT for example we yeah we Implement a lot of llms based on the same base architecture because really these are relatively small changes um it's not really um I would say Reinventing the wheel and it works well so people still yeah um keep building with that architecture here the
it all goes back to the original GPD architecture B basically um yeah so now that we are familiar with the architecture let's briefly return to the pre-training so the pre-training is essentially what creates this so-called Foundation model which is then used for fine-tuning later so I'm not going over the training Loop because um yeah it would look pretty technical if you're not familiar with training loops and it look it would look very boring to you if you are familiar with training Loops because it's really yeah just like a standard deep learning training Loop there's really
nothing different from training I would say Evolution networks multilayer pums you use the same atom Optimizer same uh learning rate schedulers like one one um cycle coine scheduler and so forth you use the same cross entropy loss so it's all the same basically that we would use when training um yeah convolution networks recurrent new network I recurrents are maybe bit different but convolution networks multilayer perceptrons and so forth and uh I would say the the only difference is really that we do that on a larger scale on multiple gpus and here the tricky part is
more like um yeah the hardware access and and that type of stuff um yeah what what do the labels look like we talked about this before already so the target um so when you train for example in classic um deep learning a convolution network is usually for some prediction task for example um let's say classifying cats versus dogs in image data and uh in LMS of course we we deal with text so what is the class label here or the thing we want to predict when we talk about um standard training Loop so here that's
really the next word in a text so like we talked about before um the next word is what we want the llm to predict so when we prepare the data we have the input here and the target is really the same as the input but shifted by one position so when the model is in the heart of the the um the next word would be the for example so really just shifting everything by by one um yeah and so usually we train for one to two EPO that's usually a good sweet spot actually most um
llms are not even trained for a full Epoch or sometimes you might read something like 1.1 EPO or something like that so just to take a step back an epoc is one pass over the training set but usually these um training sets are super large and the models are distributed over multiple machines that it's not really super I would say feasible to do the classic I mean you can but not many people do that um do the classic epoc it's more like um drawing random batches from the data set so there might be then overlaps
and some batches are seen twice some not at all and so forth but um if we think of the classic Epoch regime where EPO means one pass of the training set usually training for one Epoch is what most people do you can train a bit longer I think there was a paper looking into that um Pia uh from elua AI where they trained on duplicate so D duplicated and duplicated data and they didn't see really a difference so here on some smaller scale experiments I saw basically after two EPO you see overfitting so overfitting means
essentially um that you see a larger gap between validation and training loss so the model still improves on the training set but um it doesn't generalize to the validation set so usually one to two EPO is um Sweet Spot uh you can train more and the model will actually still become better at um generating text that looks realistic but it's yeah also memorizing the training set set a lot at some point so it's basically just yeah repeating the training set which is not a bad idea um because you can still I mean add some variety
in the sampling so I'm I don't have slides on that but you when you implement the generation basically you have settings like um top K top p and temperature scaling where you can control the amount of yeah Randomness so it doesn't regenerate the training data but uh yeah you can also just stop training early especially if you have a large data set and small if you have a small data set actually it I would say it almost makes sense to train longer until you know your LM generates coherent text and then you can control the
memorization a bit more in the sampling so one one challenge that LMS also still have is um yeah what type of memorization is good uh desired and which is not desired so I don't think there's a uh good solution yet what you almost want to do is kind of like mask um certain things to be memorized for example if you think about Chip and A lot of people use chip for you know like uh asking it history questions and of course you want the LM to memorize historic dates if it would make up let's say
the date for Independence Day and tell you it's I don't know December 12th U that would be pretty misleading so we do want the LM actually to memorize certain things from the training set it's just that we um also want wanted not to memorize everything because then it can't generate um anything else that is not in the training set so that's like it's a bit tricky I think it's an unsolved problem where yeah we do want some memorization but of course uh yeah we don't want to just you know copy paste um training data um
yeah so by the way if you are interested in pre-training my colleague um Adrian put together a studio um on on lightning on our platform where it's basically you don't have to worry about installing anything or the machines it's all in in the cloud but yeah it's a training 1.1 billion model um on 1 billion tokens takes about 4 weeks on 64 a100 gpus but just as an example um and yeah pre-training takes a long time it's uh usually not necessary if you are interested in adapting uh llm for a certain task usually we start
with a pre-trained llm but yeah if you're interested in pre-training um check out the studio by my colleague Adrien um so but that brings us also to the topic um most of the time when we work with LMS we work with pre-trained weights um so there is usually someone who was kind enough to share the weights openly there are many companies or research institutes um who do that so um in liity the library I helped developing with my colleagues um Adrien Carlos and Luca we uh yeah support more than 20 LM model weights all based
on um the same model architecture like I told you before GPD but of course with slight architecture variations but yeah we try to keep the code base um readable so that it's actually also maybe a nice library to study the difference between certain llms so in any case if you are interested in using that you can actually download weights by just LGBT download um the name of the model and then you can chat it chat with it find tune it further pre-train it or pre-train it even from scratch or or deploy it so yeah like
I said most of the time when we work with llms we are not interested so much in pre-training but um in adapting it for Downstream tasks for example by um fine-tuning llms so here um I have two steps for the fine tuning there's one the fine-tuning with class labels um it's an example to develop a classifier and then we will also talk about building a personal assistant so if you are interested for example in text classification a popular example would be classifying if a text message or email is um ham or spam so for that
I mean it's almost like a classic machine learning problem you have a label ham or spam and the text you want to classify and um all you have to do if you want to adapt an existing model so what all you have to do is you have to replace the output layer so originally the output layer in this case of the smallest GPD model has 768 hidden noes and then it maps to 50,000 output nodes so the output noes here um represent the size of the vocabulary so how many um yeah words are in this
tokenizer that the model has been trained on and so what happens usually is that it maps from this back into the words but in this case if we are only interested in classifying ham and spam we don't need 50,000 words here we only need um two so um we can actually replace this um output layer by a smaller layer so this one Maps now from 768 to yeah ham and spam instead of 5 50,000 wasn't basically so it's just also for efficiency really it helps really getting better performance out of it helps with efficiency and
so forth so it's really simple it's just like one line of code I have it in my GitHub repository one line of code you change this um layer and then you find un it and um yeah so basically we evaluate it the same way as before we track the loss um during the training this actually looks pretty good no overfitting but in addition now we have a Target task so instead of just you know looking at the next word what we can also do is we can take a look at the classification accuracy so classification
accuracy here means um how many examples it classifies correctly so how many if I have 100 um messages and uh I classify 80 correctly I would have a 80% accuracy for example so it's it's more like helps us um to evaluate the as a human the performance of the model on the target task now one might ask why don't we just train the model to um to yeah optimize or maximize the accuracy so that's unfortunately not possible because accuracy is not differentiable so we do still need the loss as the loss function to minimize during
training because yeah we can calculate a loss derivative or gradient with respect to the model weights where accuracy is not differentiable so we we can't use that to train the model but we can take a look at that during training and then we can get an idea of how good our model is so here it's almost 100% training accuracy maybe I would say 97% validation accuracy and once you're done with that you would also take a look at the test accuracy um but by the way also yeah we don't need to fine-tune all the layers
I I told you yeah you can replace that output layer and then um find to the whole model um actually you don't need to update all the layers during training so here I did some experiments and um for example on the left hand side I'm only updating the uh last layer it's a slightly different data set um so that's why the accuracies are look a bit different than on the previous slide but um so for reference here you get about 75% if you only update the last layer you get about I would say yeah 90
something percent if you update or fine-tune all the layers but you can see it's not necessary here you I'm only updating the last two layers plus the last two Transformer blocks and you can say okay it doesn't really get better after this point so it really doesn't require updating all the layers it really yeah is enough to update the last few layers here and it's also actually faster so compared to fine tuning all the layers where it takes the most time um updating only a few layers yeah is twice as fast in this case for
example okay so um this was classification fine-tuning but I think most people I would say are more excited or interested in probably instruction fine-tuning to create uh personal assistance and chat parts and so forth and that's basically what um chat GPT is personally I would say uh yeah don't underestimate um classification fine tuning I would say personally um most tasks today I I would say maybe not most I mean this is just me saying that but I think many business tasks are really classification tasks if you think about you know sorting your documents um category
izing input emails um classifying customer sentiment predicting whether a customer turns or not based on some yeah text communication and so forth I do think there are lots of practical business cases where it's actually a classification problem rather than let's say a chatbot problem of course chatbots are also super useful for certain tasks but they are more like general purpose where I think a lot of business cases um they would be solved or can be addressed with classification fine tuning which is much um cheaper and simpler to implement but anyways so let's talk about building
a personal assistant uh using an instruction data set so for that usually when we are um interested in building a personal assistant like chat GPT like chatbot on the data set looks like as follows where we have an instruction an input and an output and you know this input is also optional you can actually also append that to the instruct it's really um yeah it's it's just like a matter of format both both ways Works work but this is yeah just an example the most common example so what we would do then is we would
take this um data set and then we usually apply a prompt um template and in this case I'm using the classic alpaka style prompt template so what it is doing is it's adding this text below is an instruction that describes a task Write a response that appropriately completes the request and then it's it's basically from up here the instruction um nicely formatted and that is um what we feed to the llm so we we have this input that goes into the llm and um the llm then is supposed to generate the response here so here
the response would be great results were achieved by the team so the the instruction is rewrite the following sentence using passive voice for example um yeah and so this is how an instruction data set looks like and usually um the data set sizes I would say they range yeah I would say between, to 50,000 100,000 examples so the Paka data set back then it was the first I would say publicly available instruction data set was about 51,000 if I remember correctly and but also people showed um I think the data set was called Lima they
only had 1,000 examples and got I think even better results it was more about again the quality versus quality uh quantity so it really depends I think the more the better usually of course but you know you can get away with um thousand um thousand examples um there is an additional bonus um I would say step um it's called preference tuning and this usually follows the instruction finding because this is already a long talk I won't go into too much detail about preference tuning because it's a whole can of worms there are lots of um
yeah lots of techniques but in a nutshell what preference tuning is all about is kind of to refine the responses by the llm so when we have the input here what are the key features to look for when purchasing a new laptop um especially uh when we control the random seat for example in llm it can generate different responses or we can also provide as a human preferred response for example but uh long story short there can be different ways you can answer this answer right so there could be a more technical response um where
it says when purchasing a new laptop the focuses on key specifications it would describe the Ram size the storage type and so forth and there's let's say a more user friendly response um depends on the audience of course but so um it would then be more like think about how it fits into your daily life choose the lightweight model that you if you travel frequently by the way personally I have a MacBook Air because I do think it's actually a really good machine and I do have to travel a lot so um yeah I I
do like a lightweight laptop for my for my work for my job I have a MacBook Pro because it's you know needed more for the development work so you know it's different different uh uh yeah different considerations here both let's say are different responses a model might give maybe a model could have also a response that includes both but that could maybe be confusing for a user so you basically in preference tuning you would choose one or the other and do that for a large number of examples to kind of like steer the model more
into whats the behavior um that you want it to have so really just refinement of whether it would should be more technical or more user friendly and actually in practice it's uh mostly applied to safety um so to improve the safety of a model so for example not to give instructions on let's say how to build a bump or something like that that or not to use um spare words and so forth but then also yeah to to improve the helpfulness as well to give complete answers and not abbreviate the answers and so forth so
really it's yeah I would say a fine-tuning of the fine-tuning a fine-tuning of the instruction fine-tuning essentially like a preference fine tuning so um I have more um I've written articles about that that cover some of the techniques behind it I don't want to go too much into detail here in this talk because it's a really long talk and I think this is a really interesting topic that deserves yeah uh more time itself so but here are if you're interested some resources if you want to read more about that so um one interesting and very
important topic of course is evaluating Elms I show I showed you earlier uh in the case of classification fine-tuning how we can evaluate a classifier we can use the classification accuracy as a metric but how do we do that actually with um instruction ftuned and preference fine tuned models so one thing you may have read about is um MML um so this is a number usually between zero and 100 and when you know when op gives a web webinar webinar I mean a web uh introduction to the new uh model or Gemini the new version
is revealed or people share the new model they usually give you an mmu score so it's usually yeah score between 0 and 100 and people use that to rank um llms and this is I would say for some reason nowadays one of the most popular numbers to evaluate um LMS so what that number really means is so basically it goes back to a paper it's called measuring massive multitask language understanding and what it basically means is how good is your llm at um answering multiple choice questions so um basically the input a typical input in
mmu might look like uh which character is known for saying to be or not to be what is the question and then are four answers and the model should respond with one of those for example here in this case Hamlet and um yeah and then you basically uh calc so you calculate the score based on the number of correct answers divided by the total number of answers to get kind of like an accuracy score from that so that's why it's between zero and 100 and it's essentially saying so 100% score would mean that yeah the
model answers all the multiple choice questions in mlu correctly so it's basically just multiple choice performance I wouldn't say it's terrible or something like that but it's also not the whole story it's really just yeah multiple choice questions and you might remember from college how much we all um L um multiple choice questions and how you know how good they are in determining how smart we are really it's really just memorization in my opinion anyways um if you're interested in tasks or evaluting models like that I mean it I wouldn't say it's useless and I
I honestly so I want to be clear I really think it's useful as a metric because we can use that to really um measure performance in terms of training I'm just saying it's not sufficient to only measure mmu usually you need a bit more than that so um yeah but if you're interested um so we have also in leg for example um support for the evaluation harness with one line of code really you can evaluate mlu and other benchmarks um for a given model and so it would basically give you the score so for for
example 5 2 only gets 24% on mlu compared to let's say these here so you can say okay these models I mean it makes sense GPT 4 is much much better than a um two billion model like 5 2 um but yeah it's not the whole story so if we um want to evaluate how good an LM is it's it needs to be doing more than just answering multiple choice questions right so if we use cgbd it can do grammar correction it can rewrite your text it can up make up news stories and so forth
so um one other metric people use um well not metric more like a platform form or Benchmark is alpaka eval and that is more like a way to measure the conversational performance of an llm so here um how that works is they compare uh I think yeah see I need an LM to fix the sentence here actually should be compare the response by gbd4 preview using um oh no sorry it's actually correct so what I'm trying to say is this method works by comparing a given llm to the performance of gp4 preview and then it
uses um GPD 4 based Auto annotator to kind of so it's basically saying asks gp4 hey how does my model compare to GPT 4 preview and um it's basically doing that to calculate a win rate I think it's like based on a um how often is your given model better than gp4 so in this case if we look at gp4 Omni it's 57% of the time um better than gp4 preview so in this case is a win rate of 51 so this is a length corrected version so you can you know use use either this
or this version but um the Bott B bottom line is that GPT Omni according to this gp4 based Auto annotator is actually better than gbd4 preview question is what does it mean to be better better in what is it more correct or does the answer look more I don't know attractive or something like that so that's also not super I would say scientific but it is at least a useful thing you know it's another thing that you can add on top of um of the mmu score and the other benchmarks what's interesting I'm just seeing
here is that gp4 itself only got 38% so maybe that means that um gp4 preview was better than GPT 4 so GPT 4 got worse over time or something like that so it's kind of funny okay um moving on there's another tool that people often refer to when talking about llm performance and that is the LM sis chatbot Arena so here it's really more like a pairwise comparison so um here it's basically a crowdsourced evaluation where there are two models left and right and there's also an anonymous version where um you don't know what the
models are so you use that thing and you get two answers and then you get um two rates like you can say a is better B is better it's a tie or both are bad and then based on that it's Computing a pair wise ranking here so according to that gp40 is also the best model so basically if we take these things together if I go back a bit uh what was it here so we can see okay in this case maybe Gemini Ultra is slightly better than GPD 4 but I mean there is a
signal there because according to this one and um this one GPD 40 seems to be a pretty good model so I mean of course your mileage may vary based on what you're looking for in a model but yeah this is usually how um LM performance evaluations work like I have also my own approach um I I think the other approaches are great but in addition something quick I can do on my computer is but I I mean it's also not perfect because it's also it can be arbitrary but what I like to do is I
use just the gp4 AI to um score my answer so basically I have a given input I have a correct um output from the data set and then I have my model response and then I asked gbd4 to score the response on a scale from 0 to 100 and I get a score between 0 and 100 and usually I mean it's also pretty reliable in terms of saying which model is better if I would look at the results so it's just yet another way that's just my my personal way in addition to the other ones
um yeah so with that I hope I gave you an interesting overview of what goes into building an llm just yeah to end this talk I wanted to also give you some rules of thumb so with that I mean um how do we I mean there are so many things I covered how do we make sense of them what should you use for your given pro project for example I would say so we covered pre-training from scratch I would say pre-training from scratch um that's the most expensive thing and I would say that's almost never
necessary unless you're trying to develop a new architecture or something um or would have full control over your llm or something like that I would say that's not um necessary I think this is really yeah more like for research purposes or really if you're a big company and want to establish Your Own Foundation model for example um continued pre-training is a process where you do actually do the same as pre-training but you take an existing model and continue doing that on a smaller data set to instill new knowledge so this is um the pre-training starting
with a foundation model is actually in my opinion one of the most effective ways to instill new knowledge into an llm so if you have a model that um you know can certain thing do certain things but it has no knowledge about things from 2024 because it has been trained in 23 so in that case instead of training the whole model from scratch you can just train it on additional data from 2024 for example so basically updating your llm um fine-tuning yeah we talked about special use cases for example spam classification that's useful for that
or I mean in general text classification tasks but then also um to follow instructions to build a chatbot and so forth and then preference tuning is really to improve the helpfulness safety of um models that are intended to be for example a chatbot um yeah so just give you an example where all these things are applied so there was this um code llama model by meta AI where they developed a model specifically for coding so basically here they pre-trained a model I mean it's the same company so they for this project they started with Lama
2 but practically they also pre-trained Lama 2 because it's done all in been done in house so the pre-training was the Lama 2 creation um then they had some more continued pre-training where this was more like trained on language and then they um continued pre-training it on code specifically um and then they had some more continued pre-training for example in this so they developed multiple models in this one they trained specifically more on python code um and then they had a stage where they trained on longer contexts and um they called it fine-tuning but it's
essentially also a continued pre-training task and then uh at the last step they had instruction fine-tuning to also create an instruction variant here um yeah and with that I think we covered pretty much all of the stages of building an llm from um coding the architecture of course without showing you too much code here or not any code because it would be a very long talk otherwise uh talking about the pre-training and the fine-tuning so if you're interested I have more you know concrete examples in my um build a large language model from scratchbook where
yeah it's applying all these stages in code um so yeah to build your own small personal assistant if you're interested in that um if you looking for GPU Solutions so we are at lightning AI we are building um the lightning AI Studio which is the studio environment you can use Visual Studio code jupyter notebook and train models on uh multiple gpus and um what's nice also is you can flexibly switch between CPUs and gpus um for example so that's actually what I use for all my development work as well um we also have a lot
of examples on Lightning AI so we have a lot of Studios to um start so it's basically you can think of it as um almost like GitHub repositories but they are already um working you don't have to install anything like um package dependencies and stuff if you start a studio it's a it's a template that already runs without having to install anything yeah and so we are at the end of this presentation so if you want to contact me you can find me here and also if you would like access to the slides they are
here available on my website so I hope uh this was useful I hope it was not too long I have not checked my watch but I hope it is um below let's say 1 hour and I hope this was an informative video thanks for watching
Related Videos

13:33
Understanding PyTorch Buffers
Sebastian Raschka
4,255 views
![[1hr Talk] Intro to Large Language Models](https://img.youtube.com/vi/zjkBMFhNj_g/mqdefault.jpg)
59:48
[1hr Talk] Intro to Large Language Models
Andrej Karpathy
2,156,733 views

36:58
QLoRA—How to Fine-tune an LLM on a Single ...
Shaw Talebi
57,460 views
![The moment we stopped understanding AI [AlexNet]](https://img.youtube.com/vi/UZDiGooFs54/mqdefault.jpg)
17:38
The moment we stopped understanding AI [Al...
Welch Labs
982,715 views

56:20
What's in an LLM? Demystifying Hugging Fac...
Rotational Labs, Inc.
9,989 views

27:17
Introducing Lindy 2.0 - The FIRST True AI-...
MattVidPro AI
37,061 views

42:17
Prompt Engineering is Dead; Build LLM Appl...
Databricks
24,935 views

13:11
ML Was Hard Until I Learned These 5 Secrets!
Boris Meinardus
283,251 views

20:22
How to scrape the web for LLM in 2024: Jin...
LLMs for Devs
169,096 views

16:55
The Future of Knowledge Assistants: Jerry Liu
AI Engineer
81,866 views

50:07
Why Fine Tuning is Dead w/Emmanuel Ameisen
Hamel Husain
35,180 views

13:49
Insights from Finetuning LLMs with Low-Ran...
Sebastian Raschka
5,110 views

18:50
Is This the End of RAG? Anthropic's NEW Pr...
Prompt Engineering
51,107 views

56:58
The Three Elements of PyTorch
Sebastian Raschka
5,367 views

24:02
"I want Llama3 to perform 10x with my priv...
AI Jason
375,616 views

1:02:26
The Best Tiny LLMs
Trelis Research
13,161 views

8:31
How does ChatGPT work? Explained by Deep-F...
HowToFly
609,986 views

1:52:27
NLP Demystified 15: Transformers From Scra...
Future Mojo
69,157 views

24:20
"okay, but I want Llama 3 for my specific ...
David Ondrej
190,135 views

42:12
18 Months of Building Autonomous AI Agents...
Devin Kearns | CUSTOM AI STUDIO
80,582 views