When it comes to building AI agents, the internet is filled with guides; but the problem is, most of them just get you started with the bare bones and nothing more. Don't get me wrong, these kinds of guides are really useful and valuable, especially if you are just getting started with a topic. I mean, I make them myself all the time, but I just know that you are looking for more. You want to know how to build the best of the best when it comes to AI agents, and you don't want it to be overly
complex either. If that is you, then you are in luck, because I have something very special for you today. Over the past few days, I've been pouring my heart and soul into building an AI agent that I honestly think is the most powerful one that I've shared on my channel yet. We're going to be doing a deep dive into using Pantic AI, my favorite agent framework, with Lang Graph, an incredible agentic workflow tool, to unlock an infinite number of possibilities for building AI agent systems that can really do anything. I mean, in this video, we
are literally going to be building an agent that can make other AI agents. It's pretty insane! Also, in my last video on agentic workflows, I teased an implementation that I wanted to do with Pantic AI and Lang Graph, and a ton of you said it was a really good idea. So here it is! In my mind, using Pantic AI with Lang Graph together is an absolute game changer, and over the course of this video and future ones, I'm going to be breaking it down for you to make it super clear both why we're doing it
this way and how we can use these frameworks together. I'll also be covering a fair warning about using these kinds of setups, why this matters to you even if you're not a coder, how we can do everything locally with these agentic flows, and I want to share with you some big plans that I have coming up in the near future. I have not had this much fun building AI agents in a long time; it’s super exciting stuff! So let's go ahead and dive right into it. Okay, so before we get way ahead of ourselves and
start building an AI agent, let's get grounded into what Pantic AI and Lang Graph do for us and why they work so well together. Starting here with Pantic AI, it is a Python agent framework that makes it super easy to build AI agents while still giving us all of the customizability and control that we need to manage everything with our agents, like the testing, the function calling, and the chat history. Really, with Pantic AI, you're able to build any AI agent that you could possibly want. Within their documentation, they have a really good example that
I reference a lot with their weather agent. So, I'll have the documentation linked in the description; you can check out this agent yourself. It really breaks down in a clear way the three different parts that go into building any agent with Pantic AI, and honestly, these three parts could be applied to any framework as well. You start off with your dependencies, which are the things that your agent needs, like API keys or database connections, to do things on your behalf. The second part is the definition of the agent itself, including things like the system prompt
and the large language model that you are using for your agent. The last part of every agent you build with Pantic AI—this is what takes up most of your code—is the functions for the actual tools that allow your agent to do things on your behalf, like querying a database, using your Gmail, or, in this case, getting the weather for a specific location. So that is Pantic AI, our AI agent builder. Now, moving on to Lang Graph: Lang Graph is not a framework to build AI agents; that would overlap way too much with Pantic AI. There'd
be no reason to use both. Instead, it is an orchestrator. It is a way to take AI agents that you've built with something like Pantic AI and combine them together in a workflow so that they can actually work together and reason together about the same problem that they are tackling or the same conversation with a user. If you scroll down a little bit on their homepage, you'll see they explain it very well: it's an expressive and customizable agent workflow builder. The very important thing with Lang Graph here is they have low-level abstractions. Essentially, all that
means is they don't try to do way too much for you. There are frameworks out there like Crew AI that are really cool because they have high-level abstractions—they do a ton for you—so that in the end, you write a lot less code. But the problem with that is you will hit a wall using those kinds of frameworks where you don't have the control and customizability to really get into the intricate developments of the AI agents that you are building. This ties into what I was talking about with Pantic AI, as both Lang Graph and Pantic
AI have these low-level abstractions, meaning you still have all of the control that you need. That's what is so important about using both of these tools and also using them together, because you have all your agents built with Pantic AI, and then you connect them together with Lang Graph. That's what we're going to be doing in this video, and I even have a quick example to show you! Here, right from the LangChain blog, they have this research agent that can generate charts. It is using LangGraph under the hood to basically connect all of these nodes
together. So, I have a more zoomed-in view that we can take a look at right here. You can think about it as these agents: the researcher, the chart generator, the router. These can all be large language models that are each agents built with Pantic AI. Then, LangGraph is the orchestrator; it's what connects all these things together. It defines all the rules for all these arrows that you see, which are determining the flow of this agentic workflow. So, the user comes in with their requests, like "generate a chart of the average temperature in Alaska over the
past decade." There is a lot that has to go into this for both research and generating the chart. The first message goes to the researcher. This is where it does things like get temperature data for Alaska, and then the router decides if it has to do more research or if it can go on to generate the chart, and then give the final answer to the user. You can see here that this whole flow is very non-deterministic. It's not always the case that the researcher is going to get exactly what it needs on the first try,
and then it'll go to the chart generator, and that'll generate the chart perfectly on the first try, and then it's sent to the user. That's not going to happen most of the time. A lot of the time, there has to be some iteration where maybe you research a couple of times or you regenerate the chart a couple of times. The LLM has that intelligence to determine if that is necessary, and all that kind of non-deterministic flow in a workflow, combining these different agents together, is not easy to do without something like LangGraph. Creating these individual
agents that have the tools to do things like research or generate charts is not easy without Pantic AI or some other similar framework. This is how you can start to see the power of combining these tools together to have agents that are built very easily, with a flow that is managed very easily. Because all of these connections are set up as different nodes and edges in LangGraph, that's what we're going to dive into, and I'm going to make it super clear for you. Last thing before we dive into what we're going to be building today
with Pantic AI and LangGraph: I want to give you a fair warning for building these kinds of graph agent workflows. We’re over here back in the Pantic AI documentation; they actually have something similar to LangGraph. They have a dedicated page for this, and they have a warning for these kinds of flows. Essentially, it's just: don't over-engineer. There is a risk using these kinds of agentic workflows built as graphs that you are over-engineering, and it's overkill for what you are actually trying to build. That's kind of what they're saying here with "don't use a nail gun
unless you actually need a nail gun." They are powerful tools, but they're not the right tool for every job. What we're going to be building today, I do firmly believe, is a powerful tool. In general, when you want to build super robust agentic workflows with a lot of agents working together in non-deterministic ways, it is a really good tool. But I don't want to sit here and try to tell you that this is the end-all, be-all, when a lot of times it can be overkill. I want to really emphasize that. By the way, if you're
curious why I'm not using Graphs instead of LangGraph, it's simply because LangGraph is way more evolved and has a lot more features, some of which we're going to be using today. Maybe at some point Graphs will evolve into something I can switch to. I mean, in the end, I'm just teaching principles here; I'm not getting tied to one framework. But right now, we are using LangGraph, so that's everything for a fair warning here. But don't get too scared! I mean, Graphs and agentic workflows with graphs are still super powerful for a ton of use cases.
So, let's dive into that now. All right, welcome to Archon! This is an AI agent that builds other AI agents, all powered by, you guessed it, Pantic AI and LangGraph. I'm building this completely free and open source for you for two big reasons. The first one is that this agent literally builds other AI agents that use LangGraph and Pantic AI, so you can use this as a resource even if you are not a coder to work with these frameworks and build everything that I'm teaching here. I'm actually going to be building this out over time
into something that is super powerful, which gets into the second reason that I'm building this. In the end, Pantic AI and LangGraph are both pretty easy to work with, but the kinds of things that you can build by combining them together in very powerful ways are also going to be a bit more complicated. So, it's not easy for me in just a single YouTube video to create some masterful agentic workflow and share it with you using these two frameworks. Instead, Archon is something that I'm going to be developing in iterations as a way to teach
you Pantic AI and LangGraph, starting with something more simple and getting more complicated over time in future videos. So, you can follow along, starting simple and getting... To the point where you are a master at these two frameworks and using them together. So, currently, we're on version two, and that's what I'm going to show you how to build today with Lang graph and Pantic AI. Version one that I have right here is just a Pantic AI agent, so no L graph, and it can only build other Pantic AI agents. Then, we'll get into version two
in this video, which actually leverages an agentic workflow built with both frameworks that can build just Pantic AI agents. So, we're still getting pretty simple here, but starting to get into agentic workflows. After that, we'll get into one that can build both Pantic AI and L graph agents, and then a ton of other ideas that I have here in my vision for future iterations, like self-feedback loops, tool library integration, and supporting other frameworks like LangChain, LlamaIndex, and Crew AI autonomous framework learning. Oh, there are so many ideas that I have! Eventually, I want to turn
this into something that can actually be in an IDE, like WindSurf or Cursor. I think that would be so cool because, in the end, using those tools right now to build with Pantic AI, they completely hallucinate. LLMs by themselves, when they're not in an agent like Archon that has access to the Pantic AI documentation, do not know how to code with these frameworks. So, that is the value of Archon that I want to turn into something, in the end, that will be super easy to use and very robust, and then even integrate with other things
as well in the future, like Docker for deployments, LangSmith, mCP, other frameworks, and other vector databases besides Supabase. A ton of ideas! I'm just so excited for this, both for what it can do for us in helping us build agents, but also how it can allow me to teach you in a very clear and concise, iterative way how to work with these two frameworks and do some incredible things. All right, let's get into the code for Archon and build some awesome things with Pantic AI and L graph. All of the code that we're going to
be going over here and that I'll create with you will be in that Archon GitHub repository that I just showed you, and of course, I won't miss it; I'll have a link to it in the description as well. As promised, we're going to go iteratively through building Archon so you can understand foundationally how Pantic AI and L graph work, how they work together, and also so that you can understand why you'd want to use these more complex agentic workflow approaches with graphs versus when you might actually want to stay simple as well. In version one,
we're going to start with this here. I'm not getting right into the meat of Pantic AI and LangGraph because I really want you to understand this. Version one is going to, first of all, be a very good demonstration of how to create an agent with just Pantic AI, but then, more importantly, we're going to look at its shortcomings, and that will help us understand why we'd want to graduate into the more complex iterations of Archon that we'll be continuing to build over time, which will leverage LangGraph as well. So, in the folder right here for
version one of Archon, I have this README, which shows you exactly how to get started with specifically this version of Archon, and it talks about what exactly is implemented in this version as well. I'm going to do that for every single version I have in the iterations folder going forward, and all the code at this point in time as well, so that no matter where you jump in this journey of Archon, even if it's version six, you can still go through all of the versions iteratively to build on that foundation. Start very simple and then
get more complex as you work up to what version we're actually on. That way, you don't have to jump in the deep end. I mean, that's the point of me building this iteratively in the first place. And so that’s why we’re going to be starting with version one right here, and this is actually based on the Crawl for AI RAG agent that I’ve already built on my channel. I’m going to go through that pretty quickly here with version one since I’ve already built it on my channel, so definitely check out that video. You certainly don’t
have to; I’ll talk about it a little bit right here. But it is pretty basic overall; it’s a good idea for how to build a Pantic AI agent. So, setting up the knowledge base here, all I do, just like I did in the other video on my channel, is I fetch the Pantic AI documentation pages using the sitemap, build that up as a list that I then pass into Crawl for AI to get the contents for all of them in Markdown. Then I chunk them all up, and I put them into Supabase so that I
have it in my knowledge base for RAG using PG Vector. So, I’ve really changed nothing for this script at all, and the README talks about running this and getting the database set up and everything too. For the Pantic AI agent, again, there are three parts for any Pantic AI agent: you have the dependencies, which in this case we just need Supabase for RAG and then the OpenAI client to create our embeddings for RAG; then you have your actual agent creation, like I have right here; and then the rest of this code is the third. Part,
which is just all the tools that we want to give to our agent, um, so that it can do things on our behalf, which in this case is looking up things in the database and performing RAG. As well, the other big thing that I have right here is this massive system prompt. So, this was the big thing that I did to refactor because originally my crawl for AI RAG agent was just an agent that could answer questions on the Pantic AI docs, but I want to actually leverage the docs now to build other Pantic AI
agents, and that's what I'm telling it that it is in the system prompt now. So, I give it a nice goal here of creating Pantic AI agents using the documentation that it can fetch with the tools that I give it. I define a general structure for the different files to create for each agent that it makes, and then a lot of miscellaneous instructions just to make sure that it's not hallucinating in certain ways and that it's following the tools that I give it, um, so it's actually grounding its truth in the documentation instead of just
making up random stuff for Pantic AI. And so, it can perform RAG with this function right here to match with certain chunks in the vector database. We also have a tool to list all the documentation pages available to it, so if it doesn't just want to perform RAG but actually read an entire documentation page, it can use this tool to figure out which pages are available to it. Then, it can use our third and final tool right here to get the contents of specific pages, like maybe it wants to read up on an example in
the Pantic AI docs or the page that talks about defining tools. Whatever it might be, it can use this function to actually do that. So, this agent will intelligently use these three tools together to get all the documentation that it thinks it needs to then give us all of this code right here that we have defined in this structure to produce that Pantic AI agent for us. Now, to actually run this agent, again going back to the README, I have a Streamlit interface that I set up. I'm not going to go over this in detail
right now—just a very basic Streamlit interface to work with the Pantic AI agent, which, by the way, you can use as a reference point if you want to use Streamlit for Pantic AI, so another nice little resource for you there. But yeah, we just will run this command right here to spin up our interface. I actually already have it up and running here, um, because I'm going to show you an example run of when I was using Archon V1 just to show, again, the shortcomings of this so that we can talk about why we want
to graduate to version two. Then, I'll show you how to build that with Pantic AI and Langgraph together. So, for the example for this agent, I'm just asking it to build me an agent that can answer questions about code in a GitHub repo that I give a URL to, so essentially just the GitHub agent that I've been building as a part of my series on YouTube showing you how to build AI agents. The results that we get from this are okay. I mean, it's still actually probably better than if we were to ask Wind Surf,
GPT, or Deep Seek or something to build an AI agent with Pantic AI because those guys have no context over Pantic AI—they don't understand the documentation at all. At least this agent does, and you can definitely tell by the way that it set things up and used function decorators and things like that that it does understand Pantic AI. Though, I will say that the results are not going to run right out of the gate; it didn't define the agent correctly, the tools don't look optimal to me, I guess the dependencies are okay, but then one
big thing is it didn't say I need any environment variables even though I very much do need my OpenAI API key if I were to use it. Actually, it doesn't even tell me the model, so that's certainly broken. Also, we probably need a G API key as well unless we're only going to be cloning public repos. So, definitely not an ideal implementation overall; it kind of works, and if you have specific use cases for your AI agents that might be simple, something like just Pantic AI would suffice—you don't need the added complexity of building with
Langgraph as well. But you can see for this use case specifically, without optimizing a lot more with the system prompt or better tools or anything like that, I definitely need more. That's where a graph approach and an agentic workflow to actually make sure that it's reading through the Pantic AI documentation correctly and using it correctly is super, super important. And so, I really do want to preface what I'm about to show you by saying like maybe there are other ways to optimize besides moving to a graph approach, um, like maybe, like I said, better system
prompts or different tools to analyze the documentation differently—maybe even bringing in the Pantic AI GitHub repository. Right now, it's just the documentation pages, but overall, that might take just as much work as it is to move to this graph approach. I'm getting some really good results with version two of Archon, so with this kind of as the context as to why we really need that, let's go on to building version two with Pantic. AI and Lang graph together! So, this is the graph for the agentic workflow that we're about to make for Archon using Pantic
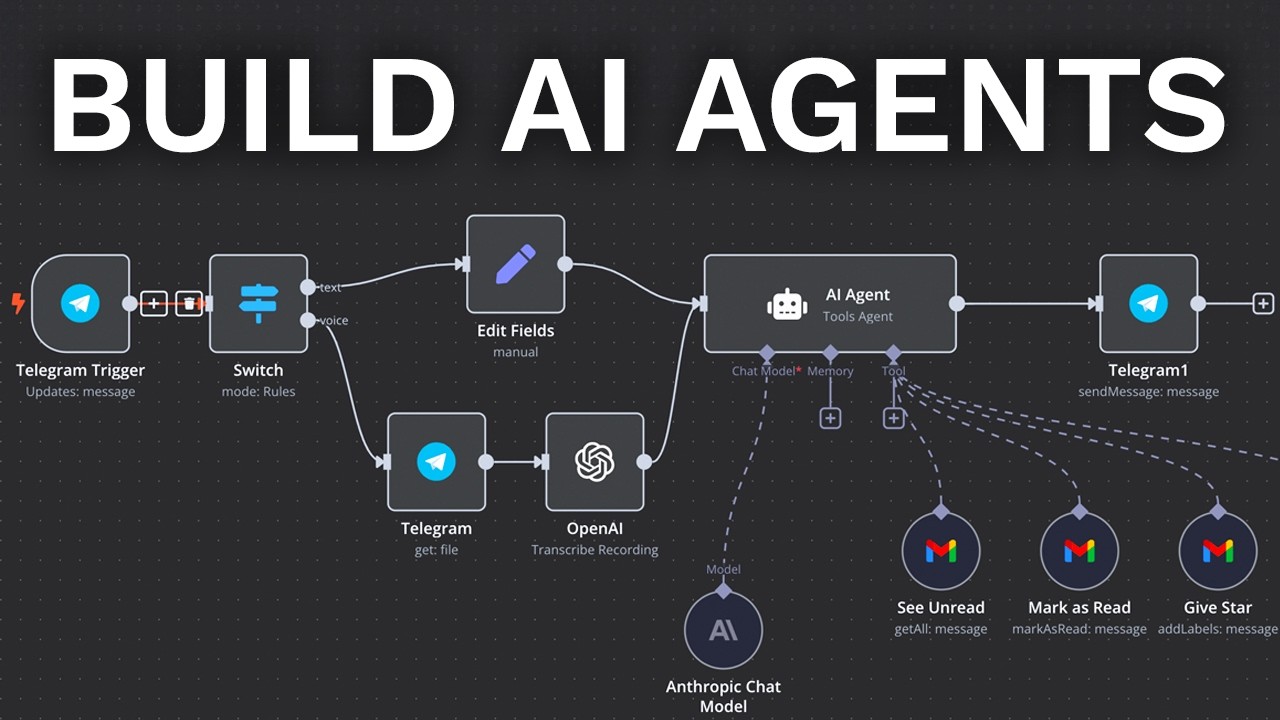
AI and Lang graph together. That's one of the beauties of using Lang graph: you can visualize your workflows without having to put in any extra work. I did not create this myself; all I did—and you can do this too—is go to version two of Archon in the GitHub repo, or it's at the root of the repo at the time of recording. Set everything up with the README, get your Python environment set up, and then run the command `lang graph dev`, and that'll spin up this studio UI, opening in your browser automatically. Then, boom! You'll have
this there, where you can visualize all the nodes in the workflow that I'm about to show you how to create from scratch. You can already see that there's a lot more going on. Essentially, version one was just the Coder agent right here. A request would come through to build an agent, and this guy would perform RAG, look at specific documentation pages, whatever, to actually produce the final agent for you. But now, with version two and LRA, we have a few different Pantic AI agents involved. First of all, we are using a reasoning LLM at the
start of the workflow—something like Deep Seek R1 or OpenAI’s GPT-3.5. This guy is going to take the requirements from the user, like the agent that they want to build, and create a full scope document outlining everything that needs to be created. It’s going to pick out certain Pantic AI documentation pages that it thinks the primary Coder agent should use RAG to look up to actually have the right context to build the agent. That alone improves the results a lot. Then, we have this loop here where the agent is going to code up another Pantic AI
agent, then get feedback from the user, and then iterate on that. We could go through this forever until the user finally decides, "Yep, it created a good agent. Let's move on." This is using a really important concept in Lang graph and other agentic workflow tools called "human in the loop." That's something I really want to demonstrate here because LLMs hallucinate all the time. So, practically any AI agent you would ever want to make would benefit from some sort of human approval involved to approve certain actions before you go on to the next stage in a
workflow, to give feedback, whatever it might be. I'm going to show you how to do that right here, and then once the user says that the AI agent is good, we have this final agent that wraps up the conversation by summarizing everything into the final AI agent for you and providing instructions to run it as well. Overall, this is a pretty basic implementation in Lang graph, but that's where I want to start with version two of Archon. A lot of the choices I made for the general structure of this graph are more just to teach
you all the concepts that I really want to focus on, like "human in the loop." Through future iterations of Archon, we’re going to really hone in on the things that actually make it work the best and start to build this out into a full workflow that will avoid a ton of different hallucinations with creating agents and things like that. Right now, we’re starting simple, but we still get a lot better results. So, let me show you this really quick. We'll use the exact same question that I asked version one of Archon, and this time we
definitely get some better results. First of all, we even get a little bit of a breakdown initially. I mean, just the fact that we give this scope document from the Reasoner into the Coder means that it has so much more information to pull from to give us a more robust response. So, we get a file breakdown here, then we get the code implementation. The tools are looking a lot better; it defines the agent and actually specifies an LLM now. I mean, maybe not the choice we’d want necessarily with GPT-4, but it defines it correctly. We
have the tools populated, the prompts file populated, and the environment variables actually make sense this time. It’s not all perfect right now, but it still looks so much better, and it even gives us some additional instructions as well. You can tell that there is a lot more involved in giving me this response compared to Archon v1, and it's all thanks to this agentic flow that has a Reasoner, a feedback loop, and then it’s got an agent at the end that can help summarize everything with instructions as well. With that in mind, we can really start
to see the power of using Pantic AI and Lang graph together. Now, let's actually go and implement this graph from scratch. Here we go! Let’s get into building Archon v2 together. We're going to do it completely from scratch because, as I promised earlier, I want this to be a true deep dive into building with Lang graph and integrating it with Pantic AI as well. Just like with v1, we have this README here that shows you how to get everything set up, including running things locally as well. So, just to make things quick right now, I'm
going to be using OpenAI, but I've actually tested this agent with Deep Seek R1 distill 7B for my Reasoner model and Quen 2.5 Instruct 14B for my coding model, and it actually kicked butt! Got some really good results using those local LLMs. The only thing I will say is you still need OpenAI for the embeddings model—that's a dependency that I'm going to get rid of in future versions of Archon so that you can do things entirely locally. But you can have your agents be local, and I got some really good results with that. So follow
along with this Remy to get everything set up just like you would with V1. A couple of other things to get set up as well, but the thing that we're going to be building from scratch here is our graph that will actually tie all these agents together, including the Pantic AI coder agent that we still have as the core agent within this workflow. As we're building out this graph, I'm going to be showing this UI, pointing out the different nodes that we're building, just to use this as a visual reference to make this entire walkthrough
as clear as I possibly can. Because even though this is a more simple L graph implementation, there are still a lot of moving parts here and different agents that we have to build and work with, and so I'm going to be using this a lot to make that pretty nice and clear. So yeah, let's go ahead and start building our graph for Archon V2. Now, if you bet $100 that at the start of all of my Python scripts I import my packages as my first step, you're going to get $100 every single tutorial that I
have here. So yeah, first thing: importing all the packages that we need for things like Lang Graph and Pantic AI as well. Then we'll load in some of our configuration, like our environment variables, which you can set all that up before you run this. So be sure to create your own version based on the example here, fill in things based on if you want to use Llama for local LLMs, go through OpenAI, whatever it might be, and then hook in your Superbase as well. We're also going to not use Logfire for our logging monitoring, which
you can use with Pantic AI; it's built in. I'm going to turn this off for now, but we'll configure this later for Archon as well. Then we're going to pull in our environment variables, and so we have our base URL. This is how we can configure if we want to go through OpenAI, Llama, or OpenRouter. Then we have our LLM API key that we're going to need for anything except for Llama; obviously, with Llama, we don't need that because it's running entirely locally on our machine. We also want to determine if we are running Llama
based on if localhost is in our base URL. The reason that I'm doing this is because Llama within Pantic AI doesn't support streaming like the other providers do. I'm not really sure why; I think it's a bug in Pantic AI that I really hope they fix. Because right now, when you use Llama, you have to wait for the entire output from the LLM before you can display it to the screen, instead of having it type out the characters as it is producing them. So, we'll just see a little bit of a difference there in how
we call our Pantic AI agents if we're using Llama or not. The next thing that we want to do is define our Reasoner agent. This is our first Pantic AI agent that is going to be responsible for basically managing this first node here that we have in our workflow to actually create the scope for the AI agent that we are building. It's going to be an OpenAI model, but we're going to override the base URL, which is how we can use a local LLM or not, and same with the API key. The model we're fetching
this from our environment variable, and we're just going to be defaulting to 03 mini if nothing is specified, but you can set up a custom Llama model that you've created. Like, I built this one that also has a larger context length so it doesn't mess things up a bunch. This is where you set up your Reasoner model, and then we create our actual Pantic AI agent with the system prompt as well—just keeping it super simple. Next, we want to create our Router agent. This guy is just going to use the same LLM as whatever we
use for our coder agent, like GPT-4 mini, Quen 2.5 instruct, whatever it might be. The reason that we need this agent here is because we have to determine within this loop when we want to break out and actually end the conversation. So the Router is going to take the latest user request and determine if they’re saying the agent is good and we can continue to finish the conversation, or do I have to go through another loop here and go back to the coder agent? That's what this guy is going to be responsible for; we'll build
that node later as well. Then we have our final agent. When the conversation is ended, this agent's only job is just to kind of summarize a conversation, give the code for the agent, and then instructions for running it as well. So the user can take the end of that conversation and just copy those commands to execute the agent on their computer. That's everything for our agents, and now we just need to define dependencies for all of these Pantic AI agents. So, we have our OpenAI client, which... We need the embeddings for Rag and then our
Superbase client as well to actually perform Rag in our Superbase database. The first thing that we need in Lang Graph is that whenever we define any graph here, we can't just go right into defining all these nodes and connecting them together; we have to manage the state for our graph. Let me actually show this here: all the different items that we have right here, that we can see in the Lang Graph UI, are all pieces of information that we want to keep track of throughout the entire execution of the graph. For example, the messages—regardless of
which node we are in—need more global state that keeps track of things the entire conversation cares about, like the scope that the Reasoner creates, which we might want to use in any of these nodes, or the message history that we're going to use in pretty much every single one of these, except this guy right here. All that is defined in the global state for our graph. For a specific execution of our graph, such as creating a single AI agent, these things are going to be set up individually for each execution of our graph. You have
something like maybe a conversation ID or a thread ID; you pass that into Lang Graph, and it's going to manage the state independently for each one of those conversation IDs. Essentially, you can have multiple executions of the graph all going on at the same time, and they're all going to manage separate state. That's how you can have these different conversations happening all at once. So that's our state. Now we can define our first node. This is going to be the defined scope with the Reasoner. This first guy right here is going to create the actual
node that's going to use the Reasoner agent that we already set up. This one is going to be pretty simple. First of all, we're going to use this function from the Pantic AI coder—I'll just show this right here. Let me scroll down; this function will fetch all of the Pantic AI documentation pages that are available in Superbase. Then we're going to define our prompt, which is going to include all these documentation pages as well. We're telling the Reasoner model that we want to create a scope: a document that outlines everything we have to create for
our AI agent. We're also telling it to pick out a few documentation pages that it thinks are relevant for creating this agent. This is a little rudimentary; there are probably much better ways to use a Reasoner to set the stage for this graph, but this is still a really solid example. Now, to actually leverage this Reasoner, it's very simple with Pantic AI: just Reasoner.doRun(). We get the scope from the result; we'll even write it out to a file here so we can see the results after it executes. I'll show this right here; we’ll get something
that kind of looks like this. I'll just kind of open that preview for the README here. So this is a scope that GPT-4 Mini actually produced. When I showed you that example earlier with version two of Archon, I actually used GPT-4 Mini for my Reasoner just to not be unfair to version one, because GPT-3 Mini is so powerful that GPT-4 Mini is a much fairer comparison to use for Reasoner LM when comparing to V1. But anyway, that’s the scope document right here, and then we're just going to return the scope. In Lang Graph, when you
want to update the global state that we’re tracking for this execution of the graph, at the end of any given node, you just have to return an object where you have the key that maps to the specific value you want to update and then the value that you actually want to update it to. So, when we first execute our graph, we're at the starting point right here; the scope value is just going to be undefined or maybe whatever we start the graph with. But once we define the scope with the Reasoner, we actually have this
state updated. So then, the scope is going to permanently have this value that the Reasoner defined unless we change it in some other node in the graph. That’s how we update the state, and that’s going to stick with us forever. We can now use this scope as a value that we put into another prompt in another node; for example, that's actually what we're going to do in a little bit here. So that is our very first node. Next up, we want to create the node for our coder agent. And again, as promised, just going through
this as our visual constantly here, we’re creating our coder agent now. This is the main guy in this workflow; it’s going to be doing most of the work, especially if the user has a lot of feedback they want to give to the coder agent. This is going to be using our primary Pantic AI Coder agent that we're using in V1. But this time, we're giving it a lot of extra context as well that the Reasoner provided in the scope. So we're creating our dependencies here, which are going to be the Superbase client and the OpenAI
client, just like with V1 of Archon. But now, we have this third dependency here because we want to inject the scope that the Reasoner created dynamically into... The system prompt for our Pantic AI Coder agent is as follows: I added this third dependency here so Pantic AI Coder's setup is exactly the same as what we have for the same file in V1, except I have this third dependency. The way that you can dynamically inject things into the system prompt in Pantic AI is by referencing "@" and then the name of the agent, like "@Pantic AI
Coder Do System Prompt." Just like the tools we have, such as the "Retrieve Relevant Documentation" tool, we have this context that Pantic AI automatically passes in as a parameter to the function. It does that for these dynamic system prompt functions as well, so we can reference the Reasoner output from the context and add that into the system prompt. Whatever we return from this function is added onto the primary system prompt that we have right here. That is how we are able to dynamically add whatever scope the Reasoner puts out into the system prompt for our
Coder agent. The reason we want to add it into the system prompt is that the system prompt is where you define the behavior and general rules for your agent. The scope of what we are creating is more of an overarching concept that we want to include in the system prompt instead of somewhere in the conversation history. I hope that makes sense. You can look at the Pantic AI documentation for dynamic system prompts if you want to dive into it more, but that is why we are adding this as a third dependency for our Pantic AI
agent. Next, we're going to get all of the conversation history that we currently have in the state right here. When we first execute it, it's going to be an empty list, but as we receive feedback from the user, this message state will be built up over time. I'll show how we do that in a little bit as well. We need to fetch this, and then we're using this model messages type adapter from Pantic AI to turn this into the format that we can actually pass into a Pantic AI agent. It's important to keep in mind
that the format we store the state in for the messages is different from what we actually need to provide to a Pantic AI agent. Therefore, we have to do a bit of conversion when we get the results from the agent and also when we refetch the message history to pass back into the agent. I'll show more about what that looks like in a little bit as well. So we get our message history, and if we are running with Olama, we can't stream the output to our interface. Thus, we have to use the concept of a
writer that we can pass into any function we want. In Lang graph, this is given automatically into any function, and we're going to call our agents, specifically "Pantic AICoder.run." We give it the latest message from the user as the current prompt, pass in our dependencies, and then pass in the message history that we created right here as well. That's how we call our agent. To explain how we get the latest user message from the state, this is actually passed into the graph through whatever user interface we are using. I'll go back to my graph right
here. When we execute our graph for the first time, "latest user message" is what we pass in. For example, I might say, "hello," and then that goes through the graph. The scope is defined. A better example would be to say, "build me a weather agent," which will be our first message from the user. The scope is then defined, leading us to the Coder agent, where the scope will be defined as whatever the Reasoner specified. The latest user message will be whatever we specified when we started the graph. In Lang graph, when we execute a Lang
graph graph in Streamlit, we just pass in this object right here where we indicate that the latest user message is whatever they input into the Streamlit UI. We leverage this within our node; in the state, we get the latest user message. This is one of the things we have defined in our global state for the graph. So, that's how we get the message from the user. We rely on the interface right here—our UI—to pass in this value to the start of our graph. I hope that makes sense. Then we write out the results. This kind
of mocks a stream because we want Streamlit to be able to expect things to be streamed out in case we aren't using AMA. However, we can't use Pantic AI streaming with AMA for some reason, so that's just a minor issue I hope they fix. If we are not using Olama, then we can actually use the "run stream" command to stream out the output and get the chunks one at a time to present to the front end in real time. Therefore, we are using the latest user message state, the dependencies, and the message history. As we
receive the chunks asynchronously, we will write them out to the front end. That is it, and now we have our result from our Pantic AI Coder. So, at this point, we have version one of our AI agent that is created in this node right here. We have executed these two; now it is time to get feedback from the user on whether we want to continue to finish the conversation or iterate more on the agent. First of all, we want to take the messages that we got back—all of the new messages from this conversation—which will include
any tool calls, as well. This is super important; this will include all the results from RAG and everything that we can add into the conversation history so that the agent retains that context. That's super important. We're adding these onto the messages, so now the messages state is going to include all the old messages, the user prompt, and all the new messages and tool calls, too. That's how we're building up the conversation history over time. Now, the next thing we want to do is add in this human-in-the-loop interrupt because now it's time to return to our
Streamlit interface, or whatever interface we are using for our UI, and get the next message from the user conversation. Another way that you can do this is to end the graph and then have a complete re-entry when the user's next message comes in. I wanted to set it up this way to show you human-in-the-loop because essentially what we're going to do is use this concept in L graph called an interrupt. That's essentially their way to do human-in-the-loop. So, we have this interrupt, and this object right here is how you can pass certain values into the
front end. For example, if the agent is requesting a certain kind of feedback, you would add that into the object here to display in the front end. In this case, I don't actually have anything extra that I want to display, so I just have an empty bracket here, and it’s going to essentially look like it's time for the user to enter their message on the front end. So, they type in whatever they want and then I’m setting the latest user message to whatever that value is that comes through when I call the graph again after
that human-in-the-loop interrupt. In my Streamlit code right here, you can see that if I'm starting the conversation, I invoke the graph this way, but then if it is a continued conversation, I use this command narrative right here, and I’m resuming with the value of user input. I’m not going to get too technical in explaining exactly how this works, but essentially using this command right here is how you resume the graph at the current execution. Whatever you pass in right here for resume equal is what is given as the value, and then we’re returning this object
right here because now we are updating the user messages state with whatever they typed in when we have that interrupt. So, I hope that makes sense; that is this node right here. Now we're going to resume execution back to the Coder Agent, and I'll show you at the end of this code how we actually set up all of these different nodes and their connections as well. But let's actually finish defining all of these nodes here. The next one that we need to define is our router, and this is the agent that is going to determine
whether the user said that the agent is good and that we can finish the conversation or whether we have to go back to the Coder Agent. So, this is my prompt for that. Based on the latest message from the user that we just set right here, I'm going to see if we want to end the conversation or continue. I could use structured output; there definitely is a better way I could do this, but this works pretty well. I haven't had an issue with this. We're just going to run the router agent with this prompt, and
then the next action is either going to be to finish the conversation or to go to the Coder Agent. If it's finished conversation, then we're going to move on to the last node in the graph; otherwise, we're going to loop back. That's what this does right here. All you have to do with Lang graph for your router nodes is just return the name of the node that you want to go to when you have a choice between going to one or the other, and we'll see that in a little bit when we actually define the
connections between our nodes at the end of this file. All right, so now the very last node that we have here is the one to finish a conversation. Just like the other Coder Agent node, we create the conversation history that we want to pass into Pantic AI. If it's an AMA, we just call the end conversation agent again, just kind of mocking the stream here—we're just running synchronously in this case. Everything else is kind of set up the same here. Then, otherwise, we’re going to call our run stream on our end conversation agent. Again, with
the system prompt, we're telling the end conversation agent to just summarize the conversation, give the final code for the agent, and then the instructions to run it as well. So, we're just going to stream this out to the front end—all the chunks for that last message. There, uh, finally update the messages in our state so that the conversation history is updated again, just like we did with our coder agent. A very similar setup here, and we're using JSON for the message state. Here, so again, we're turning this into a format that we actually want to
store. So it's actually binary JSON. It's kind of weird that Pantic AI does it this way, but when you fetch the JSON from the new messages by calling a Pantic AI agent, it turns it into binary JSON. That's what we're putting into this messages state right here. Then, when we convert it back into what we want to pass into Pantic AI using the model messages adapter, we're turning it into, um, whatever format, like the objects that Pantic AI uses to represent the different messages from that binary JSON. So that is it. Now, we can create
this builder right here based on the state that we have defined for our graph, and we can add in all of our nodes. We have our scope definer with the Reasoner LLM, our coder agent, the one that has the interrupt to get the messages from, um, us, and then finally our finished conversation agent. Now, we get to set our edges. What we just defined here are all these individual nodes, but now we have to define how they all connect together. First up, the start of our graph is going to immediately connect to the Reasoner node.
Then, we're going to connect the Reasoner to the coder agent. There's no routing at this point; it's just a straight shot that goes right to the Reasoner, then right to the coding agent. The coding agent goes right to that node that gets the next message from the user. This is where we get into a conditional edge because now we're finally at the point where we have a decision to be made. This blue node right here can either follow this blue arrow or this blue arrow, and we have to figure out what that is. The way
that we do that is we use the route user message function. So, that's this one right here, this one that we defined that returns the name of the next node to go to. If we return coder agent, we're going to go to this node right here; otherwise, if we return finish conversation, we're going to go to finish conversation. Very nice and easy to understand how these conditional edges work in Lang graph. These are the kind of things that Lang graph really helps you with. It wouldn't be easy to define all of these Pantic AI agents
and start connecting them together without having a tool like Lang graph to orchestrate it all together, have these simple routing functions, and have all this global state defined that you can update super easily. I mean, I hope you can really see how using a tool like Lang graph is so powerful, and then using Pantic AI to create all these individual agents that are super easy to run. I hope that you can just see the power of using these together. We just have our final edge here, which finishes conversation just goes to end, and then we
add in our memory so that we can actually have chat persistence for L graph. Then we compile our graph, and that's it. It is that easy. Also, this is using in-memory uh for storing all of the state for each execution of the graph. I would highly recommend using a SQLite or Postgres memory saver, which you can look at in the L graph documentation for that. I’m definitely going to be adding that in for future iterations of Archon, but just to keep things simple right now, everything is just running in memory. So, when I execute my
Python script, and I've just got it running in the terminal here, it's going to just be storing everything in my RAM for, um, you know, the chat histories and the scope, and everything that I have defined in the state right here. So that is everything for our graph. It took a little bit to go through that. That was, yeah, like a solid 20 minutes of walking through everything with L graph, but I really did want this to be a super comprehensive overview of everything that goes into this. If you have any questions at all about
anything that I might not have explained the best, and maybe the visual didn't really help you understand how something might have worked, just let me know in the comments. I love to help you understand anything that I didn't do a deep enough dive into here. But I'm going to continue on my channel just to keep doing deeper and deeper dives into L graph and Pantic AI because it is really incredible the kind of things that you can build with this. I'm not going to go over the Streamlit interface a ton right here, but like you
can see, it's only like 115 lines of code. Overall, setting up an entire chat interface to work with a Lang graph implementation is super easy. The way that you call it right here—I went over this a little bit already—but you just run this Stream command on the agentic flow. What I created at the very bottom right here is what I'm importing in my Streamlit UI, this right here, and that's all I'm using right here. So, let me go back down to it. I'm calling a stream again, passing in the latest user message, either when I'm
continuing from a human in the loop or at the very start of the conversation. Then the way that... I get this custom writer; that's kind of the last thing that I want to cover right here. When you see that I have the, uh, writer that's passed into the coder agent and also passed into finish conversation, this is automatically injected when I tell Stream or tell LangGraph that I want my stream mode to be custom. So, there's a lot of little things that took me a bit to figure out for you, so I hope this gives
you a lot of value—not having to go through the pain that I had to—just to work through a couple of the little glitches to make sure that LangGraph and Pantic AI could actually work really well together. I hope that you find that super helpful. So, that's that, and now let's just go through another quick test here and just have fun with this. Now that we have a build, if you have made it this far, congratulations! This was not a super simple implementation, but I hope that you can see how powerful this really is, and I
hope I made it very clear for you as well, and that those graph visualizations helped too. But now we get to actually play around with this and have fun. I know that we tried it out already earlier when I was comparing it to V1, but let's just have some fun with this. So, I'm going to use the full power now with 03 mini for my Reasoner and GPT-4 for the main coder agent, just going to build the example that I have right here—just a simple web search agent. Let's see how it does. And so, yeah,
we got the terminal right here; we can watch things come in in real-time. First, we have 03 mini that's going to create that scope document for context for our coding agent, and 03 mini is not the fastest because it's a Reasoner model, but I mean, actually, that was pretty quick. So, we're already going over to our Pantic AI coder agent that is performing RAG, looking at the documentation pages and now also getting those pages for extra context right here from the Pantic AI docs. And look at this—this is so cool! So, all right, we got
our dependencies right here, which are our HTTP client and our Brave API key. We're using OpenAI GPT-4 for our model; it's got a system prompt, it's defining the dependencies correctly—this is looking really, really good. Then we've got our tool that's got the decorator; this is looking good. We got our Brave API from the Pantic AI context; this is looking incredible. Perfect tool implementation—main function looks good, and then it tells us that we don't need anything in the tools and prompts because it has it defined all right here. And then for our example file, it looks
like it missed the OpenAI API key. I think we would probably need that, but at least it has the Brave API key, so not perfect. I mean, you can definitely see why we're going to need future iterations of Archon, but this is looking so good compared to Archon V1. Trying to build this kind of agent with GPT or Cursor or any kind of AI coding assistant absolutely knocks it out of the park. Just so cool to see the kind of things that it can build—so absolutely phenomenal! All right, that is a wrap for our deep
dive into Pantic AI, LangGraph, and Archon. Trust me, I have some big plans with Archon. I really want to turn this into a revolutionary open-source agent that can completely change the way that we build agents and make these coding frameworks accessible to non-coders as well. So definitely stick around and tune in for future content as well if you are interested in Archon or just interested in using Pantic AI and LangGraph, because I'm going to keep using Archon as a way to teach all this stuff in a very clear and concise way. So, if you appreciated
this content and you're looking forward to more things with Pantic AI and LangGraph, I would really appreciate a like and a subscribe. And with that, I will see you in the next video!