How GIT works under the HOOD?
202.21k views2353 WordsCopy TextShare
Tech With Nikola
Have you ever wondered how Git really works? Are you confused about what a commit is? How about merg...
Video Transcript:
hi everyone welcome to my channel my name is Nicola and in this video we will talk about git specifically we will explore how git Works under the hood let's get started if you are watching this video then you probably know what git is but let's summarize it anyway get this aversion control system which is used to track changes made to files over time it allows teams to collaborate on projects and provides a complete history of changes made to that project it also makes it easier to track down bugs and revert to previous versions if needed
understanding how git works is a valuable skill for developers because it's widely used in the software development industry let's imagine that you're building a new world changing application after creating a prototype you want to experiment with different solutions without losing your progress to be more organized you create dot versions directory and save a copy of the project there these copies are called snapshots and we never modify them if we want to make changes based on a version we copied to our working directory first make changes to it and create a new snapshot but what if
the project is large well we can save some space by referencing files that haven't changed for example using symbolic links this solution could work but it's easy to accidentally change the wrong file or copy over the snapshots so how does git actually do this well it does something similar git is a Content addressable file system which means it's a key value store where you can insert any type of content and get back a unique key that you can later use to retrieve that content this store is often called object database and the values are called
objects the key is generated from the object's content using show one hash function which gives us 160 bits long value this means that the same objects have the same key while different objects have different keys also git compresses the contents of the object using zlib library to save disk space if you use git before then you've probably seen a directory called dot git this is where git stores almost everything for example the object database is stored in the dot git objects directory and the contents of each object are stored in a file the object file
is named after its key the first byte of the key is used to name the subdirectory and the remaining part is used for the actual file containing the object so if you want to store the object with a key let's say c612 f8a git creates a file under dot git objects C6 directory and calls that file 1 2 f8a the reason git creates subdirectories is to reduce the number of files per folder given that some file systems for example FAT32 only allow up to roughly 65 000 files per folder let's go through an example where
we store our main.cpp file in git luckily git CLI already provides API to do this we can use git hash object command to store the file in the object database to see the contents of the file we can use git cat file blob and then pass the ID which is the key that we got when storing the object in the database note that we are just storing the contents of the file but not the file name or any other metadata this type of object is called a blob when we change the main.cpp file we can
store it again in the object database and it will have a different ID there are other object types in git and we'll talk about all of them the next one is tree tree solves the problem of not having the file name associated with a blob you can think of a tree as a directory in a file system it consists of other directories or files which in git terms means that the tree consists of other trees and blobs if you inspect one of the trees with Git LS3 command you can see that all the folders show
up as trees and the files show up as blobs to make a change to a file and create a new snapshot of the project we start with changing a file then store the change file in the object database and finally create a new tree for the full project let's say that we modified main.cpp nodes on the path from the change file to the root are now different all other nodes remain unchanged this means that we can reuse the whole subtree and save space this works well for large projects because majority of the tree remains unchanged
in most cases once the tree is created it's stored in the object database however we may forget the idea of the tree that contains this change so we decide to write it in a file we add a message describing the change and the author it will also be useful to know how the project changed over time rather than just the final state so each time we make a change we also store the reference to the previous change the information about a single change is called the commit commits are also objects so git stores them in
the object database we can use commit IDs to retrieve the state of the project at any point in time we can also see the history of changes unfortunately commit IDs are Shavon values which are not quite user friendly and they're difficult to remember to solve this problem git introduces a branch which is just a reference to a commit and we can give it any name next time we want to look at the project State we can refer to it via a branch name instead of using the commit ID commits are immutable because their IDs are
computed from their content if the content changes then the idea was changed too on the other hand branches are mutable so we can change them at any time in fact each time you commit a change to the git repository the current branch is automatically updated to reference the latest commit let's recap what we've learned so far git stores objects in the object database which is just a key Value Store there are three types of objects commits trees and blobs a blob represents contents of a file but doesn't include metadata such as file name a tree
represents a directory and consists of other trees and blobs a commit is a snapshot of the project with additional information such as the author time previous commit and so on each commit has a commit ID which is just a show on Cache value finally a branch is a friendly name that we can use to reference commits which simplifies how we find important versions of the project now we are going to see how we can use git to improve our workflow let's imagine that we have a product that is running in production the production version is
on the main branch and we want to add a new button to our website we don't want to break the production version while working on a new feature so we create a new branch called new button which is based on the main branch when the change is ready for the release we can update the domain Branch to reference the same commit as new button git comes with a command that does this for us and it's called git merge it tells git to merge new button Branch into the main branch in this case the merge is
very simple it just moves the branch forward but what happens if somebody reports a critical bug just before we finish the new feature let's say that the bug must be fixed immediately so we stop working on the new feature first we create a new Branch based on the current production version let's call it hotfix we fix the problem and then we merge the hotfix branch into the main branch we can now continue working on the new button feature however when the new button feature is ready for release we cannot simply update the main branch to
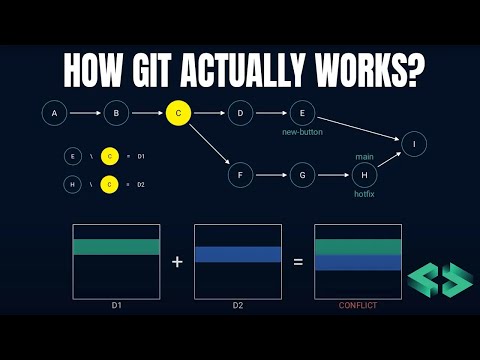
reference the new button feature anymore if we do that the changes we made in the hotfix would be gone therefore we also need to keep changes from the main branch that are not present in the new feature to do that we find the version of the project that is common to both branches then compare the snapshots from both branches with a common one and save the differences let's call these differences D1 and D2 you can use git div commands to see the difference between two commits if T1 and D2 don't overlap meaning they don't change
the same file then we can apply both changes without any issues notice that this works even if one of the features removes a file because the remote file will show up in the differences however what if D1 and D2 change the same file well we need to do something smarter for the files that are changing both branches we'll distinguish two cases if the branches don't change the same line in the file then we can apply both changes to that file after a successful merge git adds a new commit which has two parents indicating that it
is a result of a merge but what happens if both parents change the same line in the same file in that case we don't know which one to accept this is what we call emerge conflict in this case we can keep both changes in the file and maybe add special markers to indicate that someone needs to resolve the conflict manually fortunately git merge command already does all of this for us this merging process is called a three-way merge because it uses three commits to decide how to merge two snapshots that have diverged one of the
biggest downsides of merge is that it clutters the commit history git offers an alternative approach which allows us to keep the history linear which many people prefer this approach is called rebase let's say that you want to release the changes from the feature into the main branch using replay strategy in this case we say that we are rebasing feature onto the main branch so how does rebase work first it finds the commits from the feature branch that are not in the main branch these are the ones starting immediately after the common commit then the rebase
applies changes made in these commits to the main branch one by one and finally it updates the main branch to point the latest commit unlike merging rebase doesn't create an additional commit which has two parents instead the history looks as if everything was done sequentially applying changes from a single commit on top of another commit is known as cherry picking that sounds very simple but how does cherry picking actually work after all commits represent full snapshots so what does it mean to apply changes from a commit one way to think about this is to consider
the difference between the commit and its parent this would give us the changes that were made in that commit say that we want to cherry pick the commit F to the commit d this means that we want to apply the changes that get state from the commit e to the commit f let's call these changes Delta 1. so can we simply apply Delta 1 to commit d let's look at an example where this approach wouldn't work let's say that we made some changes to a file in each of these commits the file has lines L1
L2 L3 and L4 in commit d L2 L3 L4 incommit e and only L2 and L4 in commit f the difference between F and E removes the line L3 so applying this change to the committee results in the file having lines L1 L2 and L4 but is this really what we want it's potentially dangerous to ignore changes that we made to get to commit d ideally if there are overlapping changes we would like to see a conflict and let users resolve it rather than blindly applying the differences can we use the same approach as merging
to solve that remember that the merge requires three commits the base what's the merge and where to merge we have what's to merge that's the commit f where to merge it does the community but what would be the base if we use the common parent like in the merge example then we would be just merging all the changes up to commit F instead of just the Delta between E and F since we want the Delta naturally we could pick the commit e as base as a result the difference from E to F is exactly what
we want but what about the difference between e and D is this what we need for merge to work it turns out that it is let's call this difference Delta 2 and consider two cases if there is no overlap between the Delta 1 and the Delta 2 then the result of the merge is the same as applying Delta 1 to the commit D which is exactly what we want this is because applying the Delta 2 to e results in the state d if there are overlaps then the merging fails with a conflict and it's up
to the user to resolve it in some meaningful way that's all I had prepared for you about git I hope you learned something new today and if so please hit the like button and consider subscribing to my channel it would mean a lot to me and I'll see you next time
Related Videos

47:00
So You Think You Know Git - FOSDEM 2024
GitButler
1,235,404 views
46:26
How to be a git expert
Floating Little Leaves of Code
167,705 views

20:11
But, what is Virtual Memory?
Tech With Nikola
297,234 views

24:15
What does larger scale software developmen...
Web Dev Cody
1,456,354 views

9:20
How Cache Works Inside a CPU
BitLemon
776 views

19:41
Mastering Dynamic Programming - How to sol...
Tech With Nikola
738,980 views

9:39
Git MERGE vs REBASE: The Definitive Guide
The Modern Coder
122,912 views

57:39
Git Internals by John Britton of GitHub - ...
CS50
71,312 views
40:42
Git for Professionals Tutorial - Tools & C...
freeCodeCamp.org
1,701,190 views

7:25
Naming Things in Code
CodeAesthetic
2,258,148 views

15:12
The Absolute Best Intro to Monads For Soft...
Studying With Alex
661,889 views
13:58
Gordian Envelope, Elision, and Controller ...
BlockchainCommons
31 views

19:10
40 Years Of Software Engineering Experienc...
Continuous Delivery
92,222 views

10:25
The purest coding style, where bugs are ne...
Coderized
1,022,529 views
4:18
How Git Works: Explained in 4 Minutes
ByteByteGo
243,778 views

20:19
Run ALL Your AI Locally in Minutes (LLMs, ...
Cole Medin
196,962 views

5:45
Never install locally
Coderized
1,915,130 views

18:27
The intro to Docker I wish I had when I st...
typecraft
189,578 views

23:02
So You Think You Know Git Part 2 - DevWorl...
GitButler
82,621 views

19:25
Git Tutorial For Dummies
Nick White
1,213,381 views