Como uma REDE NEURAL APRENDE 🧠? (Método do Gradiente) - Redes Neurais e Deep Learning 04
5.44k views11044 WordsCopy TextShare
Universo Discreto
Nesse vídeo eu dou continuidade a série de Redes Neurais Artificiais, dessa vez focando na importânc...
Video Transcript:
Oi e aí meu amigo e minha amiga do universo físico Aqui é o Lucas do universo escapar mais um vídeo e nesse vídeo que eu vou continuar essa série de redes neurais artificiais a minha intenção é falar do básico até coisas mais avançadas de um jeito próprio meu assim que eu acho interessante no vídeo anterior eu mostrei as contas por trás de um perceptor muito básico eu acho que aquilo dá uma intuição interessante para começar a entender o que que uma rede neural artificial faz mas ainda está longe do que uma rede neural moderna realiza
Então nesse vídeo aqui eu já queria dar a intuição pouco mais completa da otimização a parte matemática que faz com que a rede não é o minimize o erro dela você tem umas questões de derivativos é derivada cálculo e eu queria mostrar um pouco dessa parte aqui nesse vídeo eu acho que vai ajudar a entender bom então vamos lá então pessoal como é de praxe aqui a gente está no nosso quadro vamos fazer algumas contas tal Vamos bater um papo então eu pego começar no vídeo anterior eu falei de um percebe o teu muito básico
próximo a a sua concepção como ele foi criado nessa vez eu vou falar de um perceptível ligeiramente modificado que é e incorpora essa ideia de método do Gradiente e tal que é pegando até o livro aqui que eu vou botar na descrição o livro Python machine learning do Sebastian errática e vá rede me jalili eu tô me baseando nele para e os cálculos aqui por trás esse vídeo E nele você tem essa apresentação aí de um presépio ligeiramente modificado muito parecido né mas que se chama adaline ele basicamente uma melhoria do PC tão tradicional que
expliquei no vídeo passado ele não é muito útil na prática Não mas ele é interessante que ajuda a gente entender os cálculos e o procedimento de uma rede neural artificial mais mostrar como vocês devem lembrar no vídeo passado que a rede neural vai se ajustando em cima de cada erro cometido né vocês devem lembrar daquele exemplo que eu usei várias vezes da Anitta se não eu recomendo para cerveja 20 passado que vai ajudar entender mas sempre que você vai fazer uma previsão por exemplo que a pessoa não vai na festa e ela vai na festa
né o seja rede neural erra ou vice-versa nessas situações a Regional se corrigir E isso não é muito eficiente na imagina uma base de dados que você tem mil exemplos mil amostras né mil pacientes com doença alb não ia ser muito prático e se a cada erro de paciente você já ajusta e a ideia que por meio dessa otimização matemática você olhar os conjuntos como as amostras como um todo né em geral a gente olha um subconjunto só por vez mas se você tiver uma base de dados pequenas dá para você olhar todo conjunto e
fazer um ajuste só para toda essa galera tipo uma média entre aspas não chega ser uma média Mas você faz um ajuste que meio que já corrigi o melhor possível ver todo aquele conjunto ou parte daquele conjunto é porque a mentira que às vezes me olhasse vou ficando muito muito grandes você já não consegue é olhar tudo de uma vez só você vai explodir a memória do seu computador fazendo isso né até por isso que esse o único idade Bete leves e olha um lote assim por vez mas eu vou chegar lá mais para frente
para a gente começar a entender o que essa rede faz a gente precisa é e usando o mesmo exemplo da Anitta a gente precisa entender algo que chamamos de função de custo função de erro que a uma função que vai dizer para a gente se a nossa rede neural Ela Está acertando ou errando toda a base para uma rede neural artificial funcionar aí em cima dessa função de custos O que que é uma função de custo tipo essa Existem várias tá que você vai usar de acordo com a sua com a situação algumas são melhores
que outros vou pegar uma aqui que é bem didática bem fácil de entender eu vou chamar ela de J W porque J não sei anotação alguns livros costumo usar j o W tem a ver com os pesos das arestas lá que conectam e os neurônios igual vídeo passado então é o mesmo w perto por exemplo se você tiver ensinando de entrada 1 2 3 e aqui é o neurônio que vai fazer o cálculo aqui você vai ter o bis tô lembrado é esse cara que vai ser o w Zoom 0 w 1w 2w é desses
w que a gente tá falando é como se essa função receber se todos os dados de uma vez só né é como se o w fosse já o seu w0 com W1 W2 W3 né E se tiver mais né bom você deve ter entendido a ideia né pão e qual que vai ser essa função aqui que a gente vai usar essa função se chama soma dos erros quadráticos e essa função aqui você vai ter um meio em x um somatório eu lembro de um colega na faculdade que ele fala Lucas o somatório é um forte
por fora do pai toma é você repete tantas vezes de tal a tal fazendo um cálculo somatório Se você não souber o que é muito parecido com esse conceito de fora acho que ajuda bastante entendeu mas eu vou mostrar aqui também esse somatório vai ser para cada amostra aí e aí voltamos a ter o nosso Y que tem a ver com os acertos nessa rede faz então a gente vai ter w&w e chapéu ao quadrado o que que é o falei w e desculpa a y y y e chapéu esse y e aqui se a
pessoa vai na festa não seguindo nosso exemplo nós vai ser para aquela Mostra aí e o que realmente está na base de dados a pessoa tá doente ou não tá é a pessoa foi para festa ou não foi enquanto um y e chapéu ele é o que a nossa rede pois viu Então a nossa rede disse que aquela pessoa aí foi na festa não né se você não tiver lembrado disso eu volto a desenhar a nossa tabelinha lá do exemplo da Anitta vocês estão lembrados tem o abc de né Que nada mais são do que
as amostras não é pessoas era pessoal 1 pessoas 2 pessoas 3 nós tem a pessoa a pessoa B C e D né E vocês devem estar lembrados que você vai ter o X10 X1 X2 e o y vocês lembram o XL é por exemplo se a pessoa tá longe ou perto da festa acho que aqui desse jeito vai ser difícil de leite o botar aqui longe o X1 e essa atacado lembra e esses dois essa pessoa vai com amigos lembra É o mesmo exemplo que a gente fez no vídeo passado se a pessoa vai ou
não no show da Anitta em cima dessas variáveis aqui e o y essa pessoa foi ou não foi tão lembrados disso se não recomendo que veja o vídeo passado aí que eu explico isso e como vocês lembram no primeiro exemplo aí você tem 00 E eu chamei de x 1 x 2 mas eu vou trocar aqui que vocês devem Lembrar que no vídeo eu usei x 1 x 2 x 2 é melhor se não confunde com 0 né que é o bis que é o nosso amigo viesse então por exemplo se a festa é longe
quer dizer se a festa é perto e se x 1 x 0 significa que a distância não é o problema o show é perto se for um significa que o show é longe e o zelo no X2 está perguntando o show é caro ou é barato no caso aí o show é barato esses dois igual significa o show é caro e esse X3 aqui igual a um significa que a pessoa vai com amigos então como vocês podem perceber aí se o show é perto show não é caro essa pessoa vai com amigos alta probabilidade dela
aí né a pessoa vai no chão sintam lembrasil mostrei isso no vídeo passado então não vou ficar repetindo muito não nesse aqui foi o exemplo que a gente montou né essa que é a nossa rede Zinha quer dizer essa nossa base de dados aí no nosso exemplo aí do show da Anitta né então e esse Y aqui pessoal é esse mesmo Y daqui é o que realmente aconteceu né então Y é o que efetivamente aconteceu com essas pessoas abcd enquanto esse chapéu aqui é o que a rede diz é só abre fazer ou disse que
a pessoa bebê vai fazer e por aí vai o legal agora eu acho que eu gosto é mais fácil da gente entender que o legal dessa nossa função uzinha Então essa função de custo JW aqui ela vai dizer para gente que a nossa rede neural Tá acertando ou errando se essa função zinha de custo de um valor igual a zero e significa que nossa rede está muito boa Tá acertando tudo se eu vou o valor muito muito alto significa que ela tá errando para caramba e vamos entender isso melhor com Exemplo né Vamos imaginar que
a nossa gente não é tipo uma rede Leide manfi ela erra tudo então ela disse 0 para o áudio se zero. B um para você e outro Deus seja ela errou tudo eu vou tudo mesmo então o que que acontece a gente jogar ali na fórmula vamos ver né então a gente vai pegar essa fórmula aqui vamos jogar a gente vai ter um meio E por que que tem esse um meio né talvez se pergunte a gente vai ver isso na parte de cálculo de derivada a gente vai entender esse somatório aqui ele vai repetir
essa soma essa essa subtração ao quadrado para cada E você tem izelli que esse cara e B que é esse cara quer dizer e um que esse cara e dois que esse cara que tu esquece cara então ue é cada amostra cada elemento que tá na sua base de dados Então a gente vai fazer então vamos botar aqui com o seu Zezinho a gente vai ter y e ali que é o real é o real que tá ali na base de dados 1 - é a proibição que a nossa rede fez ela fez uma previsão
muito ruim que é zero ao quadrado mais porque a somatória Então tá cada amostra aí para cada pessoa aí da nossa base da gente vai fazer esse cálculo né e somar com todos os Oi e ele por isso que eu falei que lembra bastante um forte né é como se fosse um foco é igual a zero que vai ser lá depois igual um que vai ser o bebê né E poder vai no caso do igual a Uh que vai ser o nosso B Ali você vai ter y e que é efetivamente O que ocorre na
base das que volta ser um ali né como a gente pode ver que a gente vai ter um menos a previsão o chapéu aqui que vai ser zero ou seja nossa rede neural e ela está errando tudo né como vocês podem ver aí mas né Continua aí o y e agora para igual a dois ver se esse cara aqui zero não é tão 0 - - o que é a previsão que a gente fez para aquele caso igual a 2 que vai ser se uma aqui ao quadrado mais aí vai repetir a mesma coisa aqui
ó 0 - 1 México Vocês pegaram a lógica né 0 - 1 ao quadrado se a gente fizer esse cálculo vai dar um ao quadrado mais 1 ao quadrado mas o ao quadrado que vai ser menos 1 ao quadrado vai dar um Então vai ser um ao quadrado um mais um mais um mais um vai dar um meio um pouquinho né a peça conta toda vai dar um meio x 4 e vai dar dois é o que que significa esse 2 esse dois é o valor mais alto possível para esse caso significa que a nossa
rede ela performula foi muito muito ruim e eu acho que fica natural fica intuitivo vocês perceberem que se a nossa rede tivesse acertado tudo Você teria algo assim e isso mudaria todas as nossas contas né até Vou tomar outra cor né eu ficar bem claro teria mudado aqui aqui aqui e aqui O que teria acontecido o menos um o quadrado da 01 - 1 ao quadrado da zero também né eu também zero também da Lia 10 x meio o quê aí daria zero então Vocês conseguem perceber que a função de pulso ela tem essa característica
em cima é uma métrica né uma medida que diz o quanto a nossa rede Tá acertando ou errando com o passar do tempo então ela acaba sendo uma medida muito boa para gente Como saber se a nossa rede neural tá indo bem ou não e nosso objetivo é que essa que usar acertos que a rede neural faz com a nossa base de dados ela se aproxime de zero ou que atinge até zero mas se atingir zero significa que a nossa região Ela Tá acertando tudo claro que aí vai ter outras outros problemas lá na frente
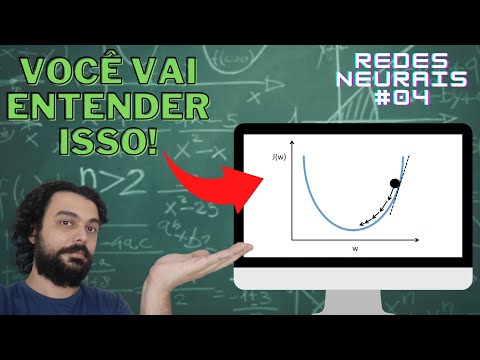
né que questão do ver Fit sobre-ajuste mas não vale a pena falar disso agora o ponto é que a gente quer aprender um jeito de fazer como que a nossa rede apanha da o caminho correto direção correta para acertar ou errar a gente consegue ver que a função de custo essa função de Hubble a medida é isso agora vamos entender um pouco melhor É continuando nessa função J aí né Essa função J né ela pode ser representado obviamente um gráfico né Existem várias várias funções de custo né Sei que eu peguei é só um E
aí é mas assim existem vários vários tipos e o ponto é que a gente pode obviamente como acabei de falar representado em um gráfico qualquer então a gente poderia fazer uma espécie de um gráfico que ao invés do X e o y tradicional né que a gente tá acostumado aí a gente pode colocar ele em cima dessa função de custo que a gente definiu então a gente pode ter o w aqui a gente pode ter o j e aí vamos entender um pouquinho é vocês lembram que não exemplo passado eu coloquei w0 tá você tem
w Zoom 0 w e W2 né Você tem todos esses casos aí eu w0 o bis e o W1 W2 W3 é referente a cada eu não tinha entrado pois está longe ou tá perto o show os atacaram trabalhar se a pessoa tem amigos ou não todos esses dados meio que estão embutidos aqui aí observa que mesmo para um exemplo simples como isso da Anitta fica difícil Ah tá pois se a gente fosse realmente fazer um gato com todos esses caras é a gente teria por exemplo lá esse cara que eu w0 aí você fala
uma coisa depois de esse seria o w um E aí eu não conseguiria desenhar o W2 W3 por quê Porque eu não consigo desenhar isso uma folha de papel numa tela não é porque aí você passa a ter uma mais do que três dimensões eu não consigo desenhar então é por isso que eu vou representar dessa maneira como vocês estão vendo aqui né mas a gente vai assumir que nesse w a gente tá embutindo w Zoom 0 w e W2 W3 no quantos dados a gente precisar né Ah é só para ter uma maneira de
representar e assim como vocês percebe a obviamente né até voltando para função aqui em cima para cada conjunto possíveis de w você vai ter um resultado diferente Projota né Ah Lucas matéria aí Aí talvez uma pergunta que suja Mas onde está o w0 aqui porque nos cálculos que a gente fez aqui não tem w0 aqui é não tem mas se você lembrar do vídeo anterior ele tá aqui né E se vocês estão lembrados que tinha função feed Z e fiz dizer é wvx um mas W2 x 2 mas w3x X3 + w0 se estão lembrados
disso E aí você tinha essa conta aqui e aí você fazia essa conta esse essa conta aqui de maior do que zero se o que o nosso se dizer que vai ser equivalente ao nosso Y com chapéu aí vai ser um e se você tiver qualquer coisa É o menor ou igual a zero isso faz com que o nosso filho dizer o nosso chapéu ali ele seja zero é tudo isso eu mostrei no vídeo anterior então acho que não faz sentido eu entrar nisso de novo mas é só para vocês lembrarem né porque tem gente
que pula às vezes só ver um vídeo específico eu tô falando ver os anteriores né mas aí Vocês conseguem entender onde que aquele conjunto w senta nessa fórmula aqui e na função aí de custos que a gente entende que os dados estão embutidos ali aí pessoal dependendo da função de custo que você tiver você vai ter representações é das mais diversas por exemplo você pode ter uma função é assim por exemplo é cada ponto possível pessoal por exemplo é esse ponto aqui você vai ter um w0 W1 W2 W3 específico e aqui se você vai
ter um outro w Zoom 0 w e W2 W3 e pulei vai né então para deixar esse bastante Claro quanto a gente trabalha com redes neurais artificiais de um jeito parecido com o vídeo anterior até você vai iniciar a sua rede noel com W Zoom 0 w e W2 W3 o quantos w se você tiver por exemplo caso Desse exemplo da Anitta num ponto Qualquer você pode iniciar um ponto é por exemplo igual esse ponto aqui ó vamos supor você começa nesse ponto aqui por exemplo se seu w00x ow10 também o 2 também e hotéis
também e se você tiver entendendo que eu tô explicando até aqui você deve estar observando que o nosso objetivo né o que a gente quer realmente conseguir aqui é chegar num ponto tipo esse porque e como vocês estão vendo aí esse J que o nosso erro então quanto mais para cima você tiver mais você está errando e quanto mais próximo de zero mais para baixo você tiver você está chegando perto de zero né esse cara que 0 né então você tá no caminho aí que você tá acertando E aí a gente começa entender a importância
da função de custa essa função aí que define a taxa dos nossos erros é para rede Noel porque se você tiver uma representação gráfica como essa o nosso objetivo é sair daqui a gente quer sair desse tonto aqui e vi um ponto aqui para baixo mas a gente quer ir naquela direção ali de acerto Então a gente vai precisar de uma ferramenta como se fosse uma bússola que o que que essa bússola faz ela quando você começa a treinar sua rede neural você vai estar no ponto Qualquer Você quer uma espécie de bússola que é
do ponto que você tiver você quer chegar naquele ponto ali próximo de zero por exemplo vai para cá bom então vai para lá bebés Isso aqui é uma reset desce Lembrando que o mundo é muito complicado pode parecer aqui para cá é um péssimo caminho lá para cá um caminho ruim mas assim você pode ter uma situação que lá para frente a sua função é assim ó E aí realmente é latim Gisele né Suponha que que ele tá atingindo o zero então de repente isso se tivesse um método alguma coisa que te disse vem para
cá vem para cá vem para cá e desce aqui a gente precisa de um método que seja tipo essa bússola que guia a gente para direção que a gente quer meu e a matemática tem isso meus amigos eu não sei se você lembra É disso mas se você calcula é a derivada num ponto Qualquer de uma função você vai ter é algo que chamamos de reta tangente até antes disso eu vou fazer o seguinte eu vou fazer tipo o anexo né aqui nesse vídeo mesmo vai ter um pedaço que eu vou botar no mínimo tarde
aqui em baixo onde eu só vou explicar a parte bem básica por trás de derivada caso você não esteja muito integrado nesse assunto né no lembra bem ou não estudou mais no contexto de redes neurais mas Digamos que por meio da se você consegue calcular algo que chamamos Opa foi sem querer que algo que chamamos de uma reta tangente é uma reta que só toca é um ponto vermelho e mais nada né um pouco difícil de desenhar aqui mas imagina uma reta que tá passando ali próximo aquele aquele garfo ali da Linha Azul mas ele
só toca o ponto vermelho então ele toca Esse ponto vermelho aqui mas não toca o restante ali do essa linha dessa curva azul aí que a gente fez e querendo ou não essa reta que passa por esse ponto ela certo como espécie uma bússola um guia pois você pode perceber pelo sentido que ele vai ajudar a gente apontar nessa direção é aonde o erro É menor né esse chapéu analogia com o pessoal usa que é como se fosse uma bola né como você se ponta que fosse uma bola se você põe uma bola assim uma
montanha no desfilar dele ela vai falar até aqui embaixo é um princípio muito parecido Mas enfim Então existe essa ferramenta da matemática que para uma função se eu tiver um e quer e um ponto tipo aquele. Vermelho eu consigo calcular aquela reta que passa exatamente naquele ponto é que ela reta vai dar uma inclinação na direção aonde você é Portanto o seu erro né como se você essa bússola nossa aí esse guia mas como assim né como que funciona essa estratégia aí né derivada né que que tem a ver então eu vou explicar rapidamente esse
conceito se você quiser pular essa parte aí do vídeo olha aqui na mesmo tá gente se você quiser acompanhar que eu acho que essa vai te dar o entendimento até mais completo disso que eu tô falando bom vamos então pegar um outro exemplo diferente então tá aqui um outro gráfico tá ó e aqui a gente tem uma uma outra função qualquer pois eu com uma função tipo essa né que eu acabei de desenhar aí como é que eu consigo né em cima daquele explicação que eu fiz Como é que eu consigo por exemplo num ponto
qualquer tipo esse ponto aqui ó uns peguei esse ponto aqui esse ponto obviamente ele vai ter um XY tá aqui já tem um y e aqui você tem um X se você vai ter um ponto Qualquer daqui x1y como é que eu faço não é para conseguir uma reta que passa eu vou só mudar um pouco desenho aqui para me ajudar nessas habilidades artísticas é de desenho que eu tenho Imagine que você tem essa reta aqui que passa exatamente naquele. X1y em justamente nesse ponto aqui x1y como é que faz para eu obter essa reta
que tem como característica principal PA é apenas aquele ponto e nenhum outro. Aí dessa desse nosso gráfico para isso eu vou precisar de um outro ponto Qualquer mais na frente né Por exemplo se eu pegar aqui mais para frente você vai ter um outro ponto aqui um ponto x 2 que aí andando para casa vai ter um ponto Y2 também então você tem: agora além dessa reta que o que eu pintei de verde aqui que eu chamei de tangente né reta tangente aquele. Você também tem algo que chamamos de reta secante o quê que é
a reta secante a reta que passa é exatamente ali e por: não é justamente aquele. X1 e X2 essa aqui é a reta secante e já que eu tenho: ali eu já consigo fazer algumas coisas eu consigo com dois pontos eu consigo obter a definição daquela reta de específica dessa reta secante E como tem várias maneiras de se a gente voltar lá para o ensino médio a gente pode pensar naquela fórmula Y2 de memes Y né daqueles posts que eu tenho ali = M que é um cara que a gente chama de coeficiente angular é
de acordo com o valor dele você vai definir inclinação dessa reta Então você tem por exemplo 1 m que vai aumentando essa reta vai inclinando né E se for diminuindo esse M essa reta também vai é mudando a sua inclinação aí para baixo e minha x X2 - x 1 mas você tem essa forma a linha aí se você não é conhecer essa fórmula até dá para obter ela também pela definição de tangente pois você pode ver que a gente vai ter um triângulo aqui tá e você vai ter um triângulo aqui e se você
assumir que esse triângulo vai ter um ângulo aqui um ângulo teto Por exemplo esse nosso amigo aqui vai ser o cateto adjacente em relação àquele ângulo e aqui você vai ter o cateto oposto Nossa amiga hipotenusa e essa tangente aí tu teto vai ser justamente o cateto oposto e pelo cateto adjacente é isso vocês observarem isso cateto oposto vai ser justamente Y2 - Y né só a gente pegar aqui Y2 a todo esse cara y1 Quem é esse cara aqui né então o que sobra que é justamente o cateto oposto ali a Y2 - y1
e a mesma coisa é aqui para baixo esse cara aqui vai ser um X2 - x 11 em sem o nosso cateto adjacente então da mesma forma que nessa fórmula zinha aqui em cima você teria my2 menos y X2 - x 1 você chega na mesma coisa é com essa definição de tangente aqui vai ser pessoal 2 - y1 X2 - x 1 o nosso até gente daquele ângulo é equivalente a esse nosso M aí essa nossa forma linha né a tangente aí desse ângulo vai justamente definir né o comportamento essa nossa reta secante aqui
é legal aí pessoal a gente pode pegar essa mesma fórmula ali NY 2 meses o X2 - x 1 e representar de uma outra maneira o tio mani a gente pode escrever um função de f de x né Y2 é a mesma coisa que f de x 2 então eu posso colocar f de x 2 - f de x 1 dividido por x 2 menos x 1 e o que que é x 2 senão o X1 mais alguma coisa X1 mais um Delta X por exemplo né Porque se você pegar x ou e somar com
alguma coisa vai dar x 2 Então vamos supor que essa diferença entre x 1 x 2 é Delta x nesse cateto adyacente que eu chamei ele é um Delta X é porque eu chamei de dar o X é só que eu tô seguindo as notações da Matemática mesmo então é eu posso modificar essa fórmula que tá f de x 1 + Delta X1 + Delta X é equivalente f x ax-2 - f de x 1 e a mesma coisa aqui embaixo o X1 + Delta x menos x 1 onde a mente quando você deve estar
percebendo aqui eu já corto x 1 x 1 vai sobrar Delta XL embaixo Então até o momento chegamos nessa forma linha aqui X1 + Delta XF de desse negócio todo mas fdx / Delta X é quem tá acostumado com cálculos já deve saber onde a gente está chegando e aí vamos lá tudo isso que a gente está fazendo todo esse artifício aqui tem como objetivo a gente chegar até aquela reta Verde ali que a reta tangente e como é que começa a fórmula consigo chegar na reta tangente é o seguinte para isso a gente vai
precisar de um cara o que a gente chama de limite in the Delta x tendendo a zero e não entender Delta x e esse cara aqui que eu mostrei para vocês que que acontece se o delta X Ele vai diminuindo está mãe devo supor Delta x original é 10 aí o diminuir K9 depositar 6:52 para 6 para 5 até chegar a zero eu fizer isso eu tô fazendo com que o Dalton acha que se aproxime cada vez mais de X1 então o x 2 ele vai colando ficando juntinho no x1 e quando isso acontece eu
faço com que a reta secante ali essa reta roxa ela vai se aproximando cada vez mais dessa reta verde né ela vai mudando assim ela vai é como se ela fosse fazer uma metamorfose da original que ela tá ela vai se aproximando até que ela Cola nessa reta tangente aí quando o delta X e por 10 Então se o delta x ele se aproxima de zero quanto mais ele se aproxime 0 mas ele vai colando ficando junto ali com a reta tangente É por isso então que seu fizer com que o delta x se aproxima
de zero eu chego na reta tangente e finalmente meus amigos a fórmula definição de uma derivada é essa daí então no fim das contas é como eu falei para vocês derivada de uma função Num ponto vai ser a reta tangente Então prova função f qualquer seu aplicar essa fórmula aqui se eu aplicar sua fórmula que eu vou obter aquela reta veja reta tangente num ponto Qualquer bom então eu já sei que por meio dessa definição aqui de derivada no ponto né É se o meu é se for na verdade o J da minha função de
custo eu vou conseguir a reta tangente no ponto Qualquer isso é um obter a reta tangente no ponto Qualquer eu volto para essa situação aqui que eu vou saber o sentido até aonde pois a reta a gente vai apontar ele vai apontando para a direção Aonde a função está se aproximando do zero ali que o JN está se aproximando do zero então no fim das contas é por isso que um cálculo é de uma derivada assim num ponto vai ser tão útil para você é por exemplo maximizar ou Minimizar funções já que ele vai apontar
para assistir na direção de ontem na direção onde a função tá crescendo onde a função tá diminuindo que é o nosso caso aqui a gente já tem que tomar um cuidado que se eu simplesmente cálculo a a derivada num ponto Qualquer E eu simplesmente oo é que tá aí eu vou apontar na direção de um erro parece que não é o que eu quero então vou ter que pegar aquela derivada ali e trocar por um sinal negativo que aí tocando com o sinal negativo eu vou e para a direção Aonde está o erro tá beleza
Lucas eu entendi mais ou menos as ideias adesivada tal e como é que a gente pega essa forma linha aqui e aplica por exemplo naquela função J ali que a gente tava discutindo é bom antes de tudo é preciso lembrar que aquele JL que eu mostrei um J mais didático não é um J que a gente vai usar e jeito de olhar as modernas mas ele acaba sendo muito útil para a gente entender em todas essas idéias aqui está sabendo o que que o que que tá acontecendo uma rede neural mais complexo Então vamos lá
como a gente discutiu a nossa função Zinha jdw é essa aqui né é meio menos é aquele somatório a t E aí é que vai ser Y em menos aí eu vou trocar aqui para se dizer que que ele é o nosso Y chapéu é só porque aqui na explicação do da derivada aqui do cálculo fica mais fácil ao quadrado que a gente vai ter que fazer gente vai ter que aplicar essa forma linha aqui do limite F tal para esse nosso efe que na verdade é JP essa mesma função aqui e um aplicar direto
assim dá muito trabalho quem já fez o curso de cálculo sabe que você calcular a derivada da é o seja obter essa reta tangente aí num ponto qualquer lembrando que derivada não é apenas para calcular a reta tangente as coisas tá é uma das possibilidades que você tem um derivadas é mais beleza jogar esse J aqui dentro dessa fórmula não é prática até por isso que já existem algumas regrinhas de derivadas prontas que você aplica para não ter que usar sua definição de limite aqui complicado e é o que eu vou fazer exatamente aqui então
vou aplicar as regras que a gente costuma usar para derivadas nesse caso não então o que eu vou fazer eu vou fazer uma derivada e assumindo que a que a gente vai derivar em função de ww ao nosso x aqui tá então a gente tá derivando aqui como se o w fosse o nosso chinelo Nossa variável o resto é tudo constante então o que que vai acontecer né Você teria algo como é uma derivada parcial mesmo não mas derivada a gente usa esse símbolo aqui que o eu não lembro o nome a gente vai derivar
em função a gente vai ter j e em função dessa nossa variável Desse nosso w aí e pessoal tudo bem Lucas do Futuro aqui só acrescentando uma observação que eu acho que vai ajudar a entender melhor essa parte é assim está calculando a derivação da nossa função de custo J justamente calcular uma reta tangente no. Wwww2w dois e depois que a gente tá fazendo esse cálculo Mas uma coisa que eu acho que é importante acrescentar é eu vou falar mais na frente no vídeo mas eu acho que já é importante falar agora é que a
gente vai ter uma equação diferente para cada w essa fórmula vai ser importante para a gente ajustar os pesos vai ter uma específica pw0 outra pw-1 e outra pw2 então a gente está calculando essa derivação aí pwj e isso obviamente vai afetar as contas na frente eu vou comentar isso já faltou no começo Mas fique tranquilo que eu vou falar disso já já tá bom e para calcular a derivada para esse cara todo eu botei menos ali mas tá errado tá que é multiplicação agora que eu vi como o meio tá multiplicando por todo aquele
casa e aquele cara é a nossa função ele vai ter justamente o w ali dentro então o meio não acontece nada com ele é meio vezes a derivada de todo esse somatório aí né de todas somatório aqui bom e o que que acontece quando a gente vai derivar alguma coisa tipo x 2 + 5 por exemplo né é pois é para como se fdx fosse esse cara a gente fosse jogar nessa fórmula quando a gente tem alguma potência tal é uma regra que a gente costuma aplicar derivada é justamente você descer aquele dois ali multiplicando
você vai ter dois XX é aí aqui você diminui o grau do polinômio de dois pão e esse cara que vai embora porque aquele se encolheu uma constante não tá sendo X uma variável então x 2 + 5 a derivada disso ou seja aplicada que ela funciona limite igual tava explicando para vocês vai dar 2x Oi e a mesma ideia aqui então esse dois é ele vai descer multiplicando bom então no fim das contas e vai ter meio vezes 2 e vezes o somatório de todo esse cara aqui vezes é a derivada ali da parte
de dentro é a derivada daquela parte de dentro ele é y e menos filhos e lembrando que fiz dizer é w0 mais W1 xx1 mas né Ele é esse cara aqui tá lembrando que no cálculo a gente deriva do lado de fora e depois vai derivando né a parte de dentro aí já não vou entrar em todos os detalhes essa regra isso não vou ter que preparar um outro vídeo para si só um curso de cálculo ele não vou ter condições de fazer isso agora não A ideia é era mais da intuição mas eu acho
que agora fica claro para vocês porque que essa função de custo tem um meio Esse e-mail é justamente para cortar com o elevador dois ali que você tinha dentro do somatório É só por isso é Para justamente essa fórmula aí dá e no ponto w qualquer Semas fácil de calcular vai ficar mais simples não ter algumas contas tal desnecessários é por isso que essa função tem isso bom então continuando aqui os nossos cálculos a gente vai ter somatório de y menos si dizer que se lembra que fizer sempre nosso amigo w0 mas abre um peixe
isso mas abre 2 X2 + W5 X2 ou quantos wcx você tiver aí multiplicado pela derivada aqui desse cara todo aí vamos entender o seguinte esse cara aqui é constante constante vai embora aí aqui você vai ter um w0 mais w1b X1 mais abre 2 x 2 é na verdade Ali você vai aplicar a distributiva pelo sinal negativo ali então você na verdade tem menos w0 o w 1 x 1 - W2 x 2 e sua se deriva esses casos em função de w esse aqui vai embora é só uma coisinha que faltou falar que
era bem importante só percebi agora É que na verdade você deriva não só em função de um WD todos os dados mas em função de WJ que na verdade você vai calcular é quando você calcular essa derivada né a gente vai chamar aqui de um derivativo você vai calcular um derivativo para cada w você é como se tivesse quando você tem essa bússola igual fiz aqui em cima apontando pé direção aonde vai o erro você é o mesmo tempo quando faz isso você já tá aprontando dizendo ó w0 aumenta um pouquinho w Diminui um pouquinho
W2 aumenta um pouquinho por aí vai tô na verdade essa fórmula aqui igual eu expliquei para vocês ele é para você vai aplicar ela para cada w é o longo é do treinamento da sua região quando eu vou fazer o cal em entrevista à rede neural acho que isso vai ficar mais fácil entender mas aí é como a gente vai fazer isso para o WJ específico né a ao derivar é apenas aquele WJ aquele W jxj vai sobreviver então por exemplo vamos por se o J fosse dois a gente consideraria todos os outros wwx um
wix3 como constantes esse aqui vai sobrar por exemplo E assumir na W2 é uma variável o que que acontece você deriva por exemplo 5x você levar a5x é a derivada disso vai ser 5 né o x ele vai embora Então na verdade o que vai sobrar vai ser o menos x 2 ali e vai ser menos a XJ ali no caso né me chamar então a gente tem essa fórmula aqui é e finalmente esse sinalzinho aqui do X Ele vai para fora você vai ter menos somatório de y e menos fiz dizer vezes XJ esse
cara que vai ser a derivada num ponto w qualquer pessoa função de custo J pelo menos para essa função de custo aí quem definiu meio vezes somatose tal tal tal então o que a gente vai fazer como é que vai ser o aprendizado aí da nossa rede a cada vez que a gente a cada é porque melhor dizendo é a cada vez que a gente pode ajustar os pesos da nossa rede neural a gente vai aplicar essa fórmula para cada www e W2 nem pulei vai todos postando a intuição é que faz a gente chegar
nessa conta e finalmente depois tudo isso que a gente discutiu vamos entender como é que a gente pega essa fórmula aqui e aplica no treinamento dessa nossa rede neural aí mais robusto usando o método do Gradiente Então vamos lá agora que assistem a nossa fórmula Zinho um só paga algumas coisas aqui é da parte inicial do vídeo que a gente não vai precisar agora e a gente não vai precisar desses caras aqui mais então vamos imaginar que novamente a gente tem o nosso super certo é um basicão e o nosso neurônio que que vai fazer
efetivamente os cálculos o nosso Bias também bom então a gente vai ter w0 aqui W1 aqui W2 aqui W2 aqui e vamos supor que todo mundo começa com zero é que é algo uma suposição razoável da gente fazer aqui como é que vai ser o aprendizado de cada w em função dessa fórmula aqui que a gente acabou de aprender já que essa fórmula ela vai dar a reta tangente no ponto Qualquer dessa nossa função de custo e assim sendo ela vai apontar na direção aonde você quer que o erro minimis né o erro diminua vamos
fazer o seguinte vamos criar uma uma outra fórmula que a gente vai chamar de Delta J esse Delta J ele vai ser ele vai apontar para a direção aonde o erro tá diminuindo dessa nossa função esse WJ de 1 g é muito parecido com que a gente fez no outro vídeo e o WJ a atualização do peso das Nossa Rede neural vai o WJ mais esse Delta RJ então Vamos definir o delta J agora em função desses cálculos que a gente acabou de aprender o delta J ele vai ter aquele learning rate que é essa
letra aqui que eu gosto de chamar Eta nessa letra grega aí x essa forma linha e de cima - eu vou botar quinta e parentes e somatório TW i - o que dizer vezes XJ no fim das contas o ajuste que a nossa rede vai fazer de tempos em tempos para cada J específico vai ser essa fórmula que eu acabei de representar é online rite no fim das contas é porque você vai dando um passinho na direção aonde o erro tá diminuindo né essa fórmula que ela vai apontar para gente a direção aonde o erro
está diminuindo você multiplica por um valor sim qualquer ele vai dando um passinho nessa direção de eu só tem que tomar um cuidado antes Se eu colocar do jeito que tá que foi o mesmo erro que eu cometi quando eu tava estudando para preparar Esse vídeo é esse essa fórmula aqui como a gente viu né esse esse cara no fim das contas ele vai ser um vetor que vai apontar na mesma direção Aonde a reta tangente está apontando mas se eu fizer isso eu vou apontar a pedir demissão do erro tão lembrados e eu não
quero isso eu quero que aponte para direção de um erro está diminuindo então pra eu fazer isso eu vou pegar essa forma linha aqui e eu vou apagar esse negativo ali pão a partir do momento que eu apaguei aquele negativo ali eu mudei a orientação do vetor que tava aprontando peso taca aponta para cá ele vai apontar É verdade no sentido contrário aonde aquela reta ali Gradiente tá apontando mas no caso aqui eu já vou estar chamando de Vetor Gradiente quero ver tu que vai tá apontando na direção que eu quero essa forma linha aqui
Delta J é ela que vai me dizer direção que eu tenho que ajustar o meu erro seja próximo de zero zero mesmo então vou pegar essa fórmula aqui Oh e vamos jogar nós vamos ver o que acontece então voltando aqui para cima não é considerando todos esses ajustes aqui será que com aqueles WC li todos zerados na nossa região ela vai obter um bom resultado eu acredito que não levam ver isso aqui na pele Então vamos calcular se a gente for calcular o ajuste de cada w em função daquelas fórmulas ele que a gente viu
e elas não mudarem eu já presumo que o meu ele tá próximo de zero não vamos ver se aplicando aquela forma ele vai ajustar o W1 W2 W3 ou não né então a gente vai ter multiplicado pelo ro que é o nosso aprendizado aí E aí a gente pode definir um valor qualquer para essa essa taxa de aprendizado e Cilene leite eu vou colocar por exemplo 0,1 esse valor é muito empírico né normalmente a gente coloca valores muito pequenininho se a gente coloca o valor muito grande é é como se aí voltando para esse gráfico
aqui é como se ao ajustar os dados eu desses altos muito exagerados por exemplo para cá E aí na próxima interação fazer o outro ajuste ele vai vir por exemplo para cá para cima né então não faz sentido botar uma taxa de aprendizado muito altos e vou botar pequena demais ele vai diminuindo muito muito devagar e com isso vai demorar muito muito muito para ele aprender mas normalmente a gente não gosta de perder muito tempo né bom então deixe 0,1 ali pois é, um 0,15 dependendo da sua situação você pode trabalhar com valores maiores ali
eu tô beleza esse cara que multiplicado aí a gente vai ter que aplicar essa forma linha ali somatório de y e menos que dizer Lembrando que fique ser o nosso famoso y e chapéu Então vai ser o que realmente está na base de dados - O que é a rede que o envio para aquele caso x XJ é isso para cada aí tá diz que é importante lembrar a gente vai fazer o ajuste considerando todos os erros e acertos da rede como um todo então ele consegue ajustar o w já considerando a rede como um
todo eu vou te botar um paletes aqui começando com o igual a zero que vai ser o nosso ali esse cara aqui é o nosso Y Então vai ser um menos aí o que é rede preview e se todos os dados forem 0 a gente tem que fazer o cálculo né vou fazer esse cálculo aí rapidinho nem é difícil né porque o que vai acontecer é que vai ser w0 vx 1100 w 2x 2w 2000 vai dar tudo zero e esse nosso filho dizer que a gente está trabalhando nesse exemplo quando esse filho dizer ele
de zero abaixo de zero significa Nossa previsão ali ele deu zero lá então a gente já tá vendo aí que ele errou e ele errou então esse cara x XJ esse XJ no caso e como editar ajustando o w Então vai ser X1 quem que vai ser o nosso amigo x 1 o nosso amigo X1 ele vai ser zero Talvez esse cara vezes eram acabou que não adiantou muito né Aí agora vai ser para próxima amostra próxima mostra vai ser o que ele foi viu para próxima mostra lá que vai ser um esse cara aqui
ó vai ser um um menos aí o que a rede preview para aquela mostra o amostra B novamente vai dar tudo Zezo né w Mas abre dois para saber como tudo tá todos os dados Estão valendo 10 nesse primeiro exemplo que vai dar zero de novo vezes x 1 ó e vai ser o X1 e da amostra B na próxima mostra ali ó então aí esse cara que vai dar um mas a gente segue nessa brincadeira a próxima mostra a gente consegue ver ali que é zero né aquele cara ali ó a 0 vai ser
0 - 0 porque esse segundo 0 ele é por todos aqueles w ali também são 10 vezes a gente Olha esses um na próxima mostra que é escala aqui ó mas a última amostra Nossa ali Oi de novo vai ser zero que a previsão daquela quarta mostra-lhe como a gente viu lá é zero também 0 - a previsão que ele vai fazer para este último caso também vai ser zero porque todos os WC lidera 10 vezes o X1 esse último cara ali ela quer dele eu cuidei ali que é um então no fim das contas
a gente vai fazer esse cálculo todo aqui me coçando que esse w aqui já é zero mesmo então W1 vai ser zero + 0,1 vezes vezes o que ela quiser ou e a quiser do também se quiser eu também porque vocês era vezes um só ali que vai dar um então o W vai receber 0,1 então a gente ajusta ali esse cara aqui serve gol Tá certo e a gente vai fazendo esse ajuste alip's para os outros w também é vamos fazer para mais um que eu acho que ajuda a entender bom W2 vai ser
W 2 + 0,1 vezes aí toda aquele cálculo de novo aí que a gente vai fazer a gente vai ficar todas as amostras Lembrando que nessa primeira iteração todas as previsões tão dando Zé Lembrando que é a gente é como se estivesse aplicando essa esse cálculo de ajuste para w Zoom 0 w e W2 W3 Make em paralelo lá então apesar de já ter atualizado o w ali para e esses cálculos continua sendo w0 Tem que atualizar todos de uma vez antes de usar os novos valores de w tá então beleza aí novamente para e
é para primeira mostra a previsão dela é u e vai ser um menos 10 Porque inicialmente Todas aquelas previsões Ele estão dando zero devido aos dados todos os dados ele se 10 vezes x Lembrando que o primeiro x 1 l e É zero eu botei uma Lima na verdade o primeiro X1 ali ele é zero eu tô mais um cálculo muito parecido até apaguei mas não deveria ter apagado não e aqui vai ser um menos 10 vezes um o que um que ele preview da próxima amostro e na verdade que o valor real é a
previsão real que está na base das menos a previsão que a gente fez * estes um aqui que a gente vai fazendo isso para cada amostra bem nem parecido que a gente fez com o w o anterior aqui vai ser zero - 10 vezes um porque para o próximo exemplo vai ser só o a previsão real a previsão que a rede fez x aquele eu só tem que tomar cuidado com uma coisa desculpa a gente aqui não é x 1 x 2 então é muito parecido mas para primeiro amostra da 1ª mostra vai ser essa
previsão aqui é o Real a o realmente a pessoa foi na festa ou não menos é o que a rede disse que a pessoa fez x esses dois ali que é zero mas já que eu tô atualizando W2 eu tenho que olhar x 2 se eu tiver atualizando W3 eu tenho que olhar x 2 né E por aí vai Então na verdade aquele cálculo que vai ser um menos 10 x 0 a exe 0 é de x 2 aqui no próximo vai ser G1 - 0 foi a previsão que ele que ele fez ali vezes
02 x 2 da segunda amostra então aqui vai ser o menos 10 vezes aqui a 0 também né Na próxima amostra vai ser 0 - 0 x 11 ele referente ao x 2 na 3ª mostra Mas finalmente 0 - 0 aqui vezes Esse é um ali no X2 da última mostra bom com isso aí é repetindo esses cálculos W2 vai ser zero e é o valor inicial mesmo W 2 + 0,1 vezes o que souber ali vamos ver se vai sobrar alguma coisa ali ó aqui nesse zero aqui vai se zero para crescer certa que
vai ser zero também então W2 vai permanecer como tá o que vai ser deve logo esse zero então W2 permanece valendo 10 né e assim sucessivamente quando você calcula W1 W2 W3 e o w0 também aí você vai novamente meu erro que tá né e repetir os cálculos eu não vou continuar fazendo uns cálculos aqui não porque acho que vai ficar uma coisa mil by as alma e maçante então vou fazer uma mudança aqui agora a partir desse momento aí vocês devem estar vendo na tela até aumentei aqui um pouquinho a fonte exageradamente para vocês
verem eu implementei aqui no colar bem eu vou colocar esse código aqui na descrição também de todo esse cálculo que a gente faria na mão mas eu vou continuar ele aqui é no parto Então a gente tem o mesmo exemplo aqui que a gente fez antes da Anitta né se a pessoa vai para o show da Anitta Não depois aí para sua coluna aqui do X1 essa coluna do X2 essa Colônia do X3 e essa última coluna ali é referente ao Y se a pessoa é uma festa nem todos estão lembrados é o show é
perto não é caro tem um amigos então eu vou então o mesmo exemplo e aqui são os WC não é w Zoom 0 w e W2 W3 E aí eu tô mostrando aqui para vocês mesmos cálculos de antes e depois vai passar um são aqui Delta J calcula aquele mesmo Delta que eu fiz do com derivativos tal que vocês viram né holereite multiplicado pelo que é a pessoa foi na festa não menos é o fim dizer que vai dizer se para aquela mostra zero ali no caso se a pessoa foi na festa não tão o
fio dizer ele vai ser a previsão de fato multiplicado pelo XL em questão como ali eh eh 0s tão lembrados que quando eu tô calculando o w Zoom 0 w e o XL vai ser um ele é fixo Enquanto Aqui para baixo por exemplo aqui já é X1 X2 e X3 é a mesma fórmula basicamente que eu mostrei antes mas já implementado aqui em Python para facilitar então quando eu rodo esse código aqui ele imprimir para gente o erro daquela primeira iteração ou seja quando eu inicializo aquela rede neural com o w Zoom 0 w
e W2 W3 com 10 o erro é um Lembrando que o erro máximo ele foi dois o erro mínimo significa que a gente acertou do deserto então eu tô no meio do caminho e se eu fizer aquele cálculo na mão é parecido com que eu fiz ele com vocês a gente vai ter que os novos dados os w calculado já os derivativos o w um e 0,1 que foi o cálculo que eu fiz ali no quadro com vocês o w 220 né que o mesmo cálculo que a gente fez o quadro W2 0,2 e o
w0 deu 0,2 Então como esses novos dados eu recálculo da Então esse código aqui embaixo vai recalcular e nessa situação o erro continuou sendo um né Então é ele se aproximou e lhe fez um ajuste ali caminhando pela função de maneira a minimizar o erro mas ainda não foi suficiente o erro continua sendo um Então é eu vou fazer novos cálculos de w repetir aquelas contas todas com os lábios anteriores ele calculei e eu vou chegar não w0 igual a o w = - 0,1 W2 - 0,2 e W2 serve Gol seu repetir esse cálculo
é aí aí eu vou atualizando esses tabus até que o meu erro seja o menor possível né aí na próxima situação a lá agora na terceira interação eu escrevi interação animais a definição correta quando a gente fala de rede neural é porque tá tão esse cara aí quando eu atualizo o w para todas as amostras a minha base de dados eu tô calculando um Apple Ué porque quando eu atualizo a essa Para Todas aquelas amostras ali igual a gente fez né e tal mas beleza aí nessa situação eu atualizo de novo o w aí ws0
villon o W vai ser zero o W 2 - 0,2 por ele vai aí na próxima interação o erro continuar meio continuar meio até que chega na sexta interação e eu chego no erro zero se o que eu consegui fazer minha região ao aprender a classificar corretamente se a pessoa vai ou não ao show da Anitta e para isso o meu W tem que meu w0 tem que ser 0,1 o meu W1 tem que ser zero meu W2 tem que ser -0,1 país ficou com um monte de ali mas acho que não tem necessidade eu
acho que é - 0,3 mesmo e o W tem que ser 0,2 esse Então como a gente pode observar eu tô fazendo com que é o meu caminho por aquela função de custo ali aquela função de erro de maneira a diminuir cada vez mais até que meu w meu jwl chegue a zero seja o meu erro Total ali seja próximo dizer no caso que o atingir zero aí só para gente realmente verificar se isso aqui tá funcionando mas se esse cara como um todo que faz sentido eu peguei uma base de dados de diabetes é
uma base de dados que tem 767 informações quer dizer pacientes com informações de sangue e tal e tal e eu joguei isso nessa rede neural muito simples que eu fiz usando o método do Gradiente para ver se ele consegue aprender aquelas ficar bem esses pacientes ou não com essa rede neural muito condimentar aqui muito parecida com aquela de cima Eu só mudei um pouquinho online leite que eu achei que poderia dar resultados melhores o w eu não inicializei com Zé não existe uma recomendação que em geral você não inicialize seu w todo com 0 que
pode complicar o demorar a convergir o ideal é você sortear valores aleatórios ou botar alguma coisa maior do que zero aí no caso iniciar dizer tudo com 0,1 aí no caso você tem acho que oito colunas aqui nessa base de dados que eu peguei vou mostrar aqui rapidinho então vocês devem tá vendo essa base de dados aqui que eu peguei simplesinho de diabetes eu nem sei o que que as colunas significam para ser honesto não lembro mas eu sei que tem a ver com informações de sangue e da arte do do da pessoa e aqui
a última coluna essa pessoa tá com diabetes ou não algo bem tradicional aí né classificação binado mesmo que bom é Se eu tentar para essa rede neural que a gente criou né bom E no caso só modifiquei o código para que aí no caso aqui ele tá mostrando o erro né na primeira iteração de 250 quanto mais amostras você tiver maior vai ser esse valor aí de erro o ponto que quanto mais próximo de zero melhor quanto mais alto sem pior e com mais amostras mais erro acumulado você vai ter e o longo do tempo
aí eu só fiz uma mudança no código como vocês viram ali em cima né eu rodei aqui na eu acabei nem comentando mas eu fiz com que a a rede neural não exemplo ali em cima atualizasse cinco vezes né e ele ajustasse todos os dados ali cinco vezes eu fiz uma mudança aqui para ele ficar ajustando o pé sempre para ver o máximo de acerto que eu consigo ter ao longo do tempo O que é bem interessante que logo de cara você já tem um acerto ali como a gente pode ver de 68 por ser
tão essa rede neural muito simplesinha que eu fiz um neurônio só basicamente mas fazendo esse ajuste usando derivativos usando o método do Gradiente ali já chega rapidamente no acerto de setenta por cento O que é bem interessante dessa peça por um código meio que feito a mão já tem tanto acerto Assim isso só mostra o potencial do que o método do Gradiente aí ele faz para gente aí ele tá imprimindo também é o erro né que aqui no caso deu 114 E aí a ideia que ele chegou mais próximo de zero e aqui os wwww2w
três essa outra rede neural aí é o ponto é que assim isso que a gente está fazendo é tão diferente assim de uma rede neural é mais tradicional é um pouco porém nem tanto essa coisa da otimização do derivativo com você atualizando os dados de maneira que você vai minimizando até que você chegue no meu erro próximo de zero até hoje todas as redes neurais fazem isso a questão é que a função de custo ali aquela função calcula o erro não é aquela que a gente usou aqui no exemplo aquela que eu peguei é super
simples super didática porque dá para calcular na mão dá para derivar lá na mão dá para explicar lá muito mais facilmente mas assim as funções que são usados elas são bem mais complicadas E você tem Vale Antes desse método do Gradiente esse método que a gente que eu mostrei para vocês ele é muito cru é mas o princípio é muito parecido você vai atualizando com o passar do tempo de maneira que você vai caminhando por aquelas e até que você se aproxime do erro ali de zero outra diferença grande é que tudo isso que a
gente fez aqui é para um neurônio só uma rede neural artificial é realmente moderna você tem vários neurônios interligados E aí você vai ter um neurônio que vai fazer um cálculo e passar a informação para outra e passar a informação para outro mas eu mostrei pra vocês o que ocorre em um neurônio só esse mesmo procedimento que eu mostrei aqui para vocês ele é aplicado é em vasos neurônios Da sua rede neural artificial ali ao longo do tempo a questão é que ele vai fazer esse cálculo e propagar esta informação de erro para trás né
mais para frente para fazer um vídeo explicando isso um pouco melhor mas a questão é que você vai ter vaso eu disse interligados que vai fazer esse cálculo E aí ó e vai passar para frente sim ou não mas 01 ou até outras coisas e quando você chega no final lá na lá na frente dessa sua região ela toda interligada você vai ter esse cálculo de erro Padre cedo ajusta o w0 ajusto tá abriu o ajuste W2 ajusto W2 e você vai calculando isso para todos os neurônios toda sua região então começa a ficar muito
muito complicado uma rede neural com várias camadas fazer todos esses cálculos na mão mas eu espero que esse vídeo é ajude vocês aí entender o que que um de ozônio faz numa rede neural como um todo um neurônio especificamente vai fazer algo muito parecido com isso que eu mostrei ao longo dessa uma hora de vídeo só que é com funções mais complicados vai fazer isso em um neurônio é de uma rede neural com vários neurônios estão vai repetir esse processo é uma Custódia absurda de vezes e tem uma outra questão importantíssima é que tudo isso
que eu mostrei aqui pra vocês é melhorando só como vocês devem e levando-me a gente não consegue obter um acerto melhor que setenta por cento como é que eu vou conseguir acertos maiores a gente vai conseguir fazer isso com redes neurais artificiais com vaso os neurônios interligados e várias camadas que é algo que eu vou mostrar a medida que os vídeos forem avançando aqui porque é mesmo usando o método do Gradiente e tal esse cara continua sendo uma versão de um perception in perception ele não consegue fazer uma separação muito inteligente muito rica ele vai
sempre errar pra caramba então o percepto ele só vai ser efetivamente bom para conjuntos muito simples exemplos tipo esse daqui eu tô usando da Anitta com uma base de dados pequena é que o neurônio só vai dizer sim ou não pés coisas se eu quiser fazer uma rede neural que saiba se fulana ou ciclano tá na imagem se aquele é um gato o cachorro se aquela música é Hot when PB enfim problemas realmente complicados você vai ter que ter vasos não eu não trabalhando junto que aí vaso trabalhando juntos eles vão analisar as minúcias os
detalhes e os menores de uma base de dados muito grandes e realmente fazer separações classificações e tal muito mais precisas então não tem como a gente ir além das capacidades aqui com uma rede simples como essa tá certo Então pessoal é basicamente isso eu espero que vocês tenham gostado desse vídeo esse vídeo vai ficar um pouco longo mas a minha intenção foi realmente mostrar a utilização mais moderna de uma rede neural e é isso né Valeu muito obrigado continue acompanhando esse esses últimos dois bichos foram muito matemáticos mas os próximos não tem mais código eu
prometo tá mas de qualquer forma e fica esse vídeo aí que eu acho que vai ser um grande uma grande maneira aí do pessoal entender a derivada ou cálculo que realmente uma rede neural tem o certo é isso valeu e muito obrigado
Related Videos

49:09
💻 REDES NEURAIS para IMAGENS e diagnóstic...
Universo Discreto
4,994 views

13:29
Machine Learning Explicado
Ciência Todo Dia
308,281 views

3:45:06
🔴 Let's build a Uber Clone with REACT NAT...
Sonny Sangha
2,500,810 views

43:25
Minha Primeira Rede Neural (Prática em Pyt...
Universo Discreto
23,061 views

46:41
PASSO A PASSO do TREINAMENTO de uma REDE N...
Universo Discreto
7,770 views

42:54
Redes neurais e multilayer perceptron - Au...
Diogo Cortiz
16,829 views

1:20:39
REDES NEURAIS CONVOLUCIONAIS: TUTORIAL COM...
Universo Discreto
6,239 views

3:27:27
3D Projection Mapping Workflow - Richard B...
TouchDesigner
165,658 views

2:49:13
SolidWorks RE Tutorial # 337: DC Motor com...
SolidWorks Tutorial ☺
1,589,573 views

12:25
DEEP LEARNING EXPLICADO
Ciência Todo Dia
263,419 views

3:38:43
Houdini Algorithmic Live #110 - Flying Spine
Junichiro Horikawa
181,930 views

12:13
Redes neurais artificiais #13: Backpropaga...
Machine Learning para humanos
2,185 views

7:48
Teoria sobre Redes Neurais Artificiais: De...
IA Expert Academy
3,255 views

48:17
Fazendo uma Rede Neural do Zero! #1 - Feed...
José Bezerra
291,701 views

3:53:40
Houdini Algorithmic Live #060 - Quadrilate...
Junichiro Horikawa
421,899 views

3:50:19
Data Analytics for Beginners | Data Analyt...
Intellipaat
1,602,886 views

9:13
Redes Neurais e Machine Learning | Nerdolo...
Nerdologia
280,962 views

50:12
Redes neurais e Perceptron - Aula 9
Diogo Cortiz
21,396 views

14:03
Gradiente Descendente Estocástico (Otimiza...
Didática Tech
12,005 views
25:43
INTELIGÊNCIA ARTIFICIAL na PRÁTICA #09: re...
Terra das Exatas
2,613 views