Unknown
0 views5637 WordsCopy TextShare
Unknown
Video Transcript:
hello everyone thank you all for your patience and we'll be starting the webinar up now so good morning and thank you for taking the time to join our webinar today today's topic will provide you with an introduction to RNA seek for those of you who are new to our webinars they're designed to provide constant and systematic training that will help keep you in whelmed formed on our products and services following the webinar we'll be sharing a copy of the PowerPoint slides as well as the recorded webinar itself I would like to point out that if
you're signed into a Google account you can ask any questions you may have in the chat box to the right of the screen please know that if you did not register earlier there's a registration link in the video description this will ensure that you get a copy of the slides and answers to any questions post it in the chat during the webinar to help frame this webinar outline here are the topics that we'll be covering first will be we'll begin with some background on gene expression followed by an intro into NGS after that we'll discuss
some of the important considerations when designing your RNA seek experiment followed by understanding the workflow analysis and interpretation of your experiment finally we'll take some time to review some projects that have shown the power and versatility of RNA seek before we begin talking about RNA seek I'd like to take a moment to introduce your speakers joining me today is my colleague dr. Chris Christopher's mention a scientific application specialist here at ABM after completing his PhD at UBC where he studied stem cell regulation he joined ABM with a passion for helping scientists achieve their goals with
nearly 10 years of experience in research and experimental design with researchers around the world and in areas ranging from cell and developmental biology to CRISPR validation and cell line engineering he can assist with nearly every product with M nearly any project you have from initial set up to post sequencing data analysis alongside him you have myself battery battery a product development specialist with over five years research experience in areas such as drug delivery lipid biosynthesis and gene therapy obtained over the course of my graduate degree at SFU our main goal is to work closely with
clients and provide them with the support that ABM has been renowned for before we begin with the core content of the webinar I'd like to take a moment to talk about applied biological materials and what our goals are ABM was founded in 2004 and has been driven to catalyze scientific discoveries in the field of life science and drug development for the last 15 years headquartered in Vancouver Canada we are one of the fastest growing biotech companies in the region and since our inception we have worked hard to become known as a reliable source for clients
such as yourselves this hard work has allowed us to expand our facilities beginning with a branch in Chang su Province in China in 2013 and a new facility in Bellingham that will be opening up later in 2019 these expansions have put us in a position to work with each and every one of you and provide the world-class service you all deserve with our team of passionate and trained scientists iBM is dedicated to empowering researchers with the latest innovations for all their scientific needs now before we discuss the core details of this webinar I feel it's
important to discuss some of the work that led us to RNA seek as well as it's important to enter research in general when studying the role of genes in development of disease there are three distinct levels we can use for examination we can study them at the DNA level by studying mutations to determine their effects on gene at the RNA level by studying gene expression and at the protein level by examining folding patterns of genes the first link in the chain leading to RNA seek is the northern bloc developed in 1977 by James Alwyn David
Kemp and George stark at Stanford University this tool was extremely useful and that it allowed for the study of gene expression via RNA detection following the northern blot was rtq PCR which was developed in the early 80s by Kary Mullis and this technique allows for the detection characterization and quantification of RNA transcripts finally the last step prior to RNA seek was the microarray which was developed by Patrick Brown at Stanford University this tool is impressive and then it can be used to simultaneously study the expression levels of thousands of genes at one time and with
that we finally come to the present RNA seek which allows us to reveal the presence and quantity of RNA in a biological sample at any given moment as well as to look at the changes in gene expression over time now when considering these three prior methods we can see that while they all had strengths such as the low reagent cost and the ability to be easily done in the comfort of your own lab there are some items that we should consider a key note is the fact that each system required prior knowledge of the chain
or the mRNA in order to be used making it impossible to use these methods to study novel genes with RNA seek on the other hand the pros are considerable well the initial cost of RNA seek is high relative to the previous methods the use of single nucleotide resolution alongside the ability to sequence new transcriptomes without prior data is a huge bonus when coupled with its massively high throughput this creates a winning combination that would be an asset to any researcher now with the advent of Illumina in 2007 we can see the near exponential increase in
the number of RNA seek publications which demonstrates the widespread use and accessibility of this tool to researcher and now we find ourselves in a position to answer the question what is RNA seek in essence RNA seek is a technique that allows us to begin with cells or tissues and examine the expressed genes by taking advantage of next-generation sequencing we can learn about changes in gene expression and identify novel splicing events and genes with this brief background I'd like to pass things over to Christopher who will begin with a brief overview of - the topics for
today's talk but first a quick reminder to everyone listening to please post any questions you may have in the in the chat box do during the course of the webinar thank you boshy for that brief introduction and thanks for joining us today for our webinar I'm gonna go briefly into an introduction to next-generation sequencing to give you a better idea of how the technology works before going into more details about RNA seek so next-generation sequencing can be used for a variety of purposes including whole genome sequencing studying changes in gene expression using RNA seek or
performing metagenomic studies with environmental samples the basic workflow for all next-generation sequencing is the same where you take input material whether it's DNA or RNA fragment it to be of a similar size ligate sequencing adapters that can then bind to the sequencer before undergoing high-throughput sequencing now there are a couple important terms to know for all next-generation sequencing approaches the first is the read a read is a sequence of nucleotides that will be sequenced so on the right you can see that there's a double-stranded DNA molecule and when it's sequenced it will sequence along one
strand which gives you the sequencing read for the nucleotides that are present we'd refer this as single and sequencing since you're only synthesizing one strand in this case the sense strand alternatively you can also use paired-end sequencing to read a fragment both strands of the molecule when you're trying to decide which option to pick for your project it's important to consider what your actual project goal is for instance single end sequencing is generally sufficient to study changes in gene expression whereas paired end sequencing is more useful for whole genome sequencing studying alternative splicing or de
novo transcriptome studies next the read can vary in length the read length is considered to be the number of nucleotides that are sequenced per read to give you an idea of the read length sizes typically for RNA seek 75 nucleotides is a common read length which would be great for studying gene expression or resequencing samples 150 nucleotides is a longer read length that's more suitable for assembling new transcriptomes or whole genome sequencing for eukaryotes and even longer reads such as 300 nucleotides are more suitable for amplicon seek as well as metagenomic studies next once you
have a sequencing read you still have to figure out how it aligns to a reference sequence so in this example you can see that there's a reference sequence in dark blue along the bottom of the image and then the read and light blue which maps to a specific location in that reference sequence if we were to look at a specific nucleotide such as this G here highlighted with a red box you can see that there are two reads in light blue that map to this eight and the reference sequence because there are two reads covering
this we describe this as 2 X coverage because you cover that nucleotide with two different readings if we look at another regions such as this C residue you can see that there are four reads that map to this specific location this would give it a coverage of 4x oftentimes there are also sites which don't have any reads that mapped them at all such as this a residue and for this site you could describe it as having zero x coverage now when you take all of these sites and add the levels of coverage for each nucleotide
together you can make an idea of the coverage for that site so in this example there are six reads for these three bases G a and C when you divide it by the number of nucleotides you would get 2x coverage so you could say that the sequencing depth is 6 reads with an average of 2x coverage for these nucleotides now for most samples you would typically sequence millions of reads to make sure as much of the entire transcript time as possible is sequenced typically bigger genomes or transcript rooms require more reads so for instance bacteria
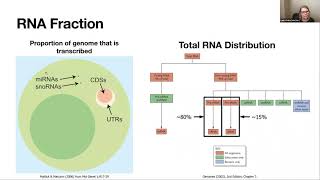
which have a genome size of about 5 million base pairs would require fewer reads and less sequencing than mammals that would have a 3 billion base pair genome or plants which would even have much larger genome sizes in terms of RNA seek for bacteria this would look like 8 million reads per sample versus 20 million reads or 40 million reads per sample from mammals and plants next I'm gonna go over a couple important things to consider when designing your rna-seq experiment first most of the RNA that's present in a cell is not actually messenger RNA
that is what most researchers want to sequence for instance if you take the total RNA present and look at the breakdown of what it's composed of you'll find that about 85 percent of it is ribosomal RNA which most researchers typically do not want a sequence next about 10 to 12 percent is transfer RNA again which most researchers are not interested in sequencing for their projects mRNA itself is typically about 2 to 3 percent of the total RNA present in a cell and then an even smaller percentage than this is composed in micro rna's long non-coding
rnas circular RNAs and other sequences so if your starting point is this large population of total RNA you have to find a way to enrich for what you actually want a sequence in that sample there are two basic ways that we can do this the first of which is poly a enrichment where we use special beads that can bind to the poly a tails on mrnh and scripts to pull them out of the population of total RNA and enriched for poly a sequences alternatively if you want to study mRNAs as well as small RNAs like
micro RNAs you can use a treatment called our RNA depletion which will selectively remove the are RNA sequences from the total RNA population if you're working with eukaryotic samples you can use either option poly a enrichment or RNA depletion if you're working with prokaryotic samples however you absolutely have to use an RNA depletion treatment because prokaryotic cells typically do not have poly a tails on their mRNA transcripts next you need to consider how you're designing your project and what your goal is if your goal is to Nauvoo transcriptome assembly for a species which previously hasn't
had a sequence transcriptome you typically want greater sequencing depth and longer reads to help with the assembly next if you only want to study changes in gene expression to see if a particular gene increases or decreases in response to a stimulus using single end sequencing is typically sufficient finally if you want to identify novel transcripts or new alternative splicing events you would typically want to use a greater sequencing depth and paired end sequencing next I'm gonna go over briefly the general RNA seek workflow for most projects this is highlighted here and I don't want you
to focus too much on this but there are four basic steps beginning with library preparation before a sample is input into the sequencer followed by bridge PCR sequencing by synthesis and finally analysis at the outset of the project you'd have to input your starting material assess its quality and convert it to DNA typically when we begin with a sample we would ask is the mRNA degraded if it's not degraded we can perform poly a selection before converting the RNA into DNA this conversion from RNA into DNA is done to increase this ability of the molecule
and ensure success with sequencing if the mRNA transcript is degraded however we can do special treatments that can repair the transcript to still provide sequence below material for the project next once the material has been converted into DNA it will likely be of different sizes because different mRNA transcripts are generally of different lengths so the next step would be to fragment the DNA into uniform sizes to make sure each fragment is equally likely to be sequenced the next step is to ligate sequencing adapters so that the DNA fragments can bind the sequencer itself once this
is done you can input the material into the sequencer and you'll go through a step called cluster generation or bridge PCR now oh sorry I'm just gonna jump back briefly bridge PCR is one of the most important steps for sequencing because when you're sequencing these molecules it's not possible to sequence a single DNA molecule in the sequencer itself you first have to generate clusters of identical molecules that are then sequenced together so in this diagram in part one you can see a DNA molecule that binds to the flow cell of the sequencer the molecule then
bends over and binds to the other adapter on the flow cell before DNA synthesis begins to form a double-stranded DNA molecule you can see this now in part 3 where the sequencing reaction that generated the double strand DNA occurs in step four you can see that you now have two molecules in two clusters this process is repeated many times in panel five until you have sufficient DNA molecules to be able to sequence each cluster now importantly you need to know the concentration of your library so that you can avoid over clustering over clustering happens when
the cluster density is too high this leads to the Machine not being able to accurately read each cluster to determine what the DNA sequences and generally leads to the entire sequencing run failing the opposite problem you also want to avoid which is under clustering this happens when the cluster density is too low and it leads to an overall lower sequencing output and again makes it hard for the sequencer to read what the sequences at that cluster next I'll briefly go over aluminous technology for sequencing by synthesis to give you an idea of how the sequencing
process itself actually works so when you have the template DNA it will have a primer that will prime it for DNA synthesis that binds to the flow cell next you have individual nucleotides that have fluorescent dyes bound to them which can be used during the synthesis reaction in the next panel you can see that the a nucleotide has been added to the sequence all the nucleotides that didn't bind because they don't have a complementary base on the other strand would be washed away after the step occurs there be a fluorescent emission and response to light
stimulus from the nucleotide that's been added that will be imaged by the sequencer after this step the fluorescent editor the fluorescent site is cleaved from this molecule washed away and then the process repeats again once this repeats a to the end of sequencing you will then be able to have the Machine go through and read each of the fluorescent signals that occurred to piece together what the sequencing was for that molecule at every stage of sequencing though quality controls essential and there are three core technologies we use to perform this QC the first of which
is qubit that can measure DNA concentration the Agilent bio analyzer which can assess your DNA library and how well it's been fragmented and then qpcr which can be used to determine how much of the actual prepared library is sequence of all so you're starting one of the most important things you can do is to run a RN angel to determine if your material is possibly degraded if you have a high quality sample you should see a few distinct bands in your gel versus if the sample is degraded you'll typically see a large smear in that
Lane if you do have this degradation we can use special kits to recover degraded RNA or to reverse formaldehyde modification to RNA if your sample was fixed prior to extraction and this can help provide you with sequence little material for RNA seek next if you have a low amount of starting material the first thing you have to do is actually know what this quantity is and for that we can use cubit to measure the concentration of nucleic acids that are present in a sample this is crucial for library preparation if you do have a low
amount of starting material we can use special kits that can amplify the mRNA that is present using the poly a tail prior to RNA seek next after you have the material that's been converted from RNA to DNA and you go through the fragmentation step the Agilent bioanalyzer comes in handy to tell you how efficient the fragmentation was and to give you an idea of the average fragment size in your sample and then after you've liked it at the adapters successfully qPCR becomes essential and I'll go through these two steps next with Agilent when you input
your sample the data that you get from it is effectively a graph that tells you how big the fragment sizes are that are present in your sample and their general distribution so in this graph here you can see that there are two peaks on the left and right hand side of the graph I've highlighted them here in red boxes for you what you actually want to look at though is the fragment size highlight in this green box which tells you roughly that your fragments are on the higher end of the range of fragment sizes which
is a good result which you want to have for sequencing the alternative is when you have an uneven distribution of fragment sizes with no large fragments and typically these smaller fragments are more difficult to see and are less likely to give you a high-quality sequencing result or lead to a failure in sequencing so we generally want to avoid this next with qPCR this gives you a helpful metric that you can't measure with qubit now remember qubit can tell you about the amount of nucleic acids present in a sample but qPCR can tell you how much
of the nucleic acids are actually sequencing bull and have adapters like age them correctly next I'm going to go over a bit more of rna-seq analysis and interpretation of the data so the general workflow once the next-generation sequencing has been complete is that you will go from raw data to a format called fast queue with intermittent steps before you can do data analysis the raw data from the sequencer you will generally never see because either software or the sequencer itself will process it into fast queue now fast queue is simply the FASTA format a text-based
format for depicting nucleotides with the quality control info from that sequencing run in that particular sequencing read if you want to see what this actual fast queue data would look like shown here to the right and you can see that it's largely a line of alphanumeric text but it's kind of hard to understand what's going on the important sequence information here is highlighted in the red box which is the actual sequencing result from this particular sample from this particular cluster next you have to figure out how to use the actual data before you can do
the analysis that you're interested in so with fast queue this is generally what we provide for each next-generation sequencing project whether it's RNA seek whole genome seek or another type of sequencing if you wanted to work with this you'd have to take fast queue data first and align it to the reference sequence we briefly went over the alignment of reads earlier in the presentation this is one of the crucial steps at the end of sequencing after you've done the alignment which can generally be done using different software you would then have to normalize your data
before you can begin the alysus and generate beautiful figures that you can eventually publish with your manuscript I'm gonna over a bit of how the data is normalized it's important to normalize your data for two main reasons but first is you need to normalize the number of reads per sample because some samples may receive different reads next you need to normalize the number of reads per gene because genes are different lengths and you have to take this into account I'll go over this a bit more in the next few slides for instance if you have
three samples sample a B and C you would generally want each sample to be sequenced an equal amount but because of stochastic differences in sequencing that cannot be controlled you generally have different sequencing outputs for each sample in this example sample a would have about 20 million reads sample B about 30 million reads and sample C would have 10 million reads if you didn't normalize your data without doing any processing you would think that samples C has one-third of the gene expression of sample B for instance or that sample a and sample B's expression levels
are different even if they may be identical secondly you need to normalize relative to the length of the gene and the number of reads for that gene in this example you can see gene a is about one KB and gene B is 2 KB or twice that length for this example gene a has 5 reads that map to it and gene B has 10 reads but gene B is twice as long if you didn't normalize your data you would think that gene B is expressed twice as highly even if that may not be the case
so you'd then have to normalize the data there's a useful metric we can use that can account for differences between samples and between genes this is called fragments per kilobase of transcript per million mapped reads or fpkm this is a way to look at the relative expression of a transcript proportional to the number of cDNA fragments that it originated from or sorry that originated from it so fpkm is essentially the normalized estimation gene expression based on the RNA sequencing data or another way to think of this is fpkm helps normalize the differences in the amount
of reads per sample as well as the number of reads proportional to how long a given gene is in this specific example once we've normalized gene a and gene B you can see that the fpkm value is 2 for both indicating that both these genes despite having different lengths and different numbers of mapped reads have the relatively similar expression level if you were to compare this to a treated normalized sample you'd then be able to include whether or not expression has increased or decreased relative to control using this normalized data set next once you have
this what type of analysis can you actually do the first is you can use heat maps to look at large changes in expression between a control sample and a tree example and to visually detect depict increases or decreases in gene expression next you can perform principal component analysis to see if any of your samples have different changes in gene expression that may correlate and be related to the treatment conditions they underwent next you can also do functional annotation of differentially expressed genes with this this allows you to look at genes that have increased an expression
decreased in expression or remain the same and see if there's any similar pathways or processes that they might be involved in such as metabolism inflammation or even a mean response next I'm gonna hand it back to boshy to go over a couple examples of researchers that have used RNA seek in their studies thank you for that excellent talk Christopher as he just mentioned I'll be taking a few minutes to discuss some of the studies that people have used to demonstrate the power and versatility of our NAC and after that we'll wrap up the webinar and
proceed to the Q&A session now the first of these projects is the encode project which focused on identifying genome-wide regulatory regions in different cell lines this was then followed by the model organism encode project which aimed to provide by the biological research community with a comprehensive encyclopedia of genomic functional elements in the model organism C elegans and D Milano gaster this was a huge undertaking and was aimed at helping to better understand the downstream effects of regulatory regions next we have the Cancer Genome Atlas Project which took advantage of RNA seek to analyze thousands of
cancer patient samples to better understand the underlying mechanisms of malignant transformation and progression and cancer finally the use of RNA seek in medicine has been substantial as it's allowed for researchers to expand their work into personalized medicine which can have a huge impact on genetic disease and with that we now come to the wrap-up portion of the webinar and as a thank you we'd like to offer your promo code for 25% off of your RNA sequencing bioinformatics package which you can see here and will also be included in our follow-up email and now that we've
finished through with the background of RNA seek let's take a moment to examine some of the resources that ABM offers first make sure to check out our website where all of our resources are collected this includes our knowledgebase articles as well as our YouTube videos and blog posts to help provide you with the tools you need for your experiments now not only do we have a diverse selection of educational material we also have an incredibly knowledgeable technical support team who can guide you through your experiments as well as a dedicated customer service team to ensure
that you receive your items in a timely manner if you have any questions about our materials or services you can always reach out to us by phone email online chat and in addition we have a comprehensive frequently asked questions section on our website so you can always browse through and see if you can find the answers there thank you for your taking the time to join us today you just give you a heads up we'll be having a for another webinar on whole genome sequencing so keep an eye out for an invitation from us soon
thank you for taking the time to join us today and now we'll proceed over to the Q&A section all right so you just take a moment give us a moment please just to go through all the questions and we'll start up with as many as we can get through all right so we've got one here from Ian oh and the question is how long does it take to do library prep as well as QC and sequencing so Chris so generally from the time we receive your samples to do a preliminary QC the library prep process
the Agilent QC and prepare your samples for sequencing the process from the date we get your samples until you get your data is about four to six weeks now a large part of that time isn't set aside for the actual sequencing process which can generally be done in about a week but it's to ensure that we have sufficient samples in order to set up the sequencing run if you have a large number of samples we can possibly provide you with the results from your sequencing in a matter of a few weeks that sound look good
answer so now let's look for another one we've got one here from Andrew Cushman he's asking if if he's done his experiment and he has the raw data can he give us the raw data and have us do the sequencing for him thanks Andrew that's a great question so if you do have raw data and you don't know what to do with it we have a dedicated in-house bioinformatics team that can effectively do nearly any type of analysis that you need for your project we have a number of bioinformatics services listed on each of our
NGS pages including for RNA seek if there's something that you're interested in that we don't list if you simply send us an email we can work with our bioinformatics team to set up a custom analysis package for you and generally get the results to you in a matter of a few weeks depending on how challenging the analysis is and how much custom software we have to develop for you that's perfect all right now we've got another one here from Kate what happens if my samples fail QC Kris again thanks Kate for that great question so
if we receive your samples and there's any issue during the QC process we'll reach out to you and let you know if we would like to ask for new samples or if there's steps we can take to try to address it and process your samples and possibly still achieve a high-quality sequencing results if for whatever reason your samples don't pass the additional QC we reach out to you again and ask you if you'll be able to provide new samples or provide with alternative options for proceeding that was a great answer Chris we're just scrolling through
the questions all right so we have one more I think this I think we've only got time left for one more question so we've got one here from and why she Ann's asking if she can submit one sample and use it for both RNA seek and MI RNA seek or do they need to have do they need to submit separate samples for each one it's actually quite a popular question so when we're trying to process samples from micro RNA seek we need to use special kits that are unique for small RNA sequences this would be
different than what we would normally do for regular RNA seek so if you did want to do both rna-seq and micro RNA seek we'd either ask for twice the starting sample amount or two separate samples in order to process this that was fantastic and I hope that was helpful and that made sense let me see if we've got we have if we're able to answer any more all right so unfortunately I think we are a little up on time right now so we'll do is we'll go through the questions we'll write up some answers and
we'll be emailing that out to you along with the slides for this webinar so once again thank you all for joining us today and we hope you have a great rest of the day thank you
Related Videos

32:16
Getting Started with Whole Genome Sequenci...
Applied Biological Materials - abm
66,390 views
17:41
Single cell RNA sequencing overview | ScRN...
Animated biology With arpan
14,840 views
58:58
Webinar #11 - Beginner's guide to bulk RNA...
opar
15,252 views

13:00
Gene Silencing Methods: CRISPR vs. TALENs ...
Applied Biological Materials - abm
174,869 views

31:50
Setup RNA-Seq Pipeline from scratch: fastq...
Bioinformagician
95,864 views

18:26
StatQuest: A gentle introduction to RNA-seq
StatQuest with Josh Starmer
494,617 views

31:11
Introduction to RNA-Seq for Researchers
Iowa Institute of Human Genetics
96,025 views

24:37
Single Cell Sequencing - Eric Chow (UCSF)
iBiology Techniques
241,409 views

6:08
The Basics of Lentivirus Production/Packag...
Applied Biological Materials - abm
65,594 views

7:38
Next Generation Sequencing - A Step-By-Ste...
ClevaLab
311,079 views

9:30
1) Next Generation Sequencing (NGS) - An I...
Applied Biological Materials - abm
1,371,556 views

57:35
How to analyze RNA-Seq data? Find differen...
Candice Chu, DVM, PhD, DACVP
216,854 views

6:39
Introduction to Cell Transfection: Part 1
Applied Biological Materials - abm
3,888 views
9:28
RNA Seq: Principle and Workflow of RNA Se...
CD Genomics
15,681 views

33:29
NGS Data Analysis 101: RNA-Seq, WGS, and m...
Applied Biological Materials - abm
80,998 views

5:22
Multiplicity of Infection (MOI): What is i...
Applied Biological Materials - abm
64,112 views

1:18:01
How I analyze RNA Seq Gene Expression data...
Bioinformatics Coach
28,856 views

25:32
DESeq2 Basics Explained | Differential Gen...
Bioinformagician
82,553 views