Is Most Published Research Wrong?
5.99M views2207 WordsCopy TextShare
Veritasium
Mounting evidence suggests a lot of published research is false.
Check out Audible: http://bit.ly/Au...
Video Transcript:
In 2011 an article was published in the reputable "Journal of Personality and Social Psychology". It was called "Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect" or, in other words, proof that people can see into the future. The paper reported on nine experiments.
In one, participants were shown two curtains on a computer screen and asked to predict which one had an image behind it, the other just covered a blank wall. Once the participant made their selection the computer randomly positioned an image behind one of the curtains, then the selected curtain was pulled back to show either the image or the blank wall the images were randomly selected from one of three categories: neutral, negative, or erotic. If participants selected the curtain covering the image this was considered a hit.
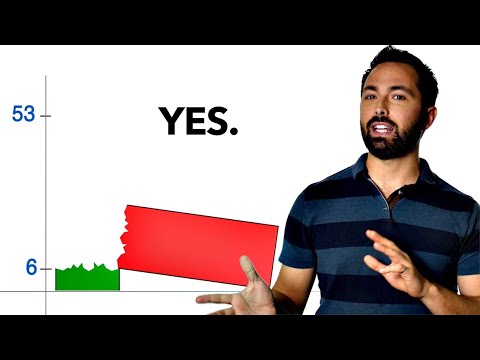
Now with there being two curtains and the images positions randomly behind one of them, you would expect the hit rate to be about fifty percent. And that is exactly what the researchers found, at least for negative neutral images however for erotic images the hit rate was fifty-three percent. Does that mean that we can see into the future?
Is that slight deviation significant? Well to assess significance scientists usually turn to p-values, a statistic that tells you how likely a result, at least this extreme, is if the null hypothesis is true. In this case the null hypothesis would just be that people couldn't actually see into the future and the 53-percent result was due to lucky guesses.
For this study the p-value was . 01 meaning there was just a one-percent chance of getting a hit rate of fifty-three percent or higher from simple luck. p-values less than .
05 are generally considered significant and worthy of publication but you might want to use a higher bar before you accept that humans can accurately perceive the future and, say, invite the study's author on your news program; but hey, it's your choice. After all, the . 05 threshold was arbitrarily selected by Ronald Fisher in a book he published in 1925.
But this raises the question: how much of the published research literature is actually false? The intuitive answer seems to be five percent. I mean if everyone is using p less than .
05 as a cut-off for statistical significance, you would expect five of every hundred results to be false positives but that unfortunately grossly underestimates the problem and here's why. Imagine you're a researcher in a field where there are a thousand hypotheses currently being investigated. Let's assume that ten percent of them reflect true relationships and the rest are false, but no one of course knows which are which, that's the whole point of doing the research.
Now, assuming the experiments are pretty well designed, they should correctly identify around say 80 of the hundred true relationships this is known as a statistical power of eighty percent, so 20 results are false negatives, perhaps the sample size was too small or the measurements were not sensitive enough. Now considered that from those 900 false hypotheses using a p-value of . 05, forty-five false hypotheses will be incorrectly considered true.
As for the rest, they will be correctly identified as false but most journals rarely published no results: they make up just ten to thirty percent of papers depending on the field, which means that the papers that eventually get published will include 80 true positive results: 45 false positive results and maybe 20 true negative results. Nearly a third of published results will be wrong even with the system working normally, things get even worse if studies are underpowered, and analysis shows they typically are, if there is a higher ratio of false-to-true hypotheses being tested or if the researchers are biased. All of this was pointed out in 2005 paper entitled "Why most published research is false".
So, recently, researchers in a number of fields have attempted to quantify the problem by replicating some prominent past results. The Reproducibility Project repeated a hundred psychology studies but found only thirty-six percent had a statistically significant result the second time around and the strength of measured relationships were on average half those of the original studies. An attempted verification of 53 studies considered landmarks in the basic science of cancer only managed to reproduce six even working closely with the original study's authors these results are even worse than i just calculated the reason for this is nicely illustrated by a 2015 study showing that eating a bar of chocolate every day can help you lose weight faster.
In this case the participants were randomly allocated to one of three treatment groups: one went on a low-carb diet, another one on the same low carb diet plus a 1. 5 ounce bar of chocolate per day and the third group was the control, instructed just to maintain their regular eating habits at the end of three weeks the control group had neither lost nor gained weight but both low carb groups had lost an average of five pounds per person the group that a chocolate however lost weight ten percent faster than the non-chocolate eaters the finding was statistically significant with a p-value less than . 05 As you might expect this news spread like wildfire, to the front page of Bild, the most widely circulated daily newspaper in Europe and into the Daily Star, the Irish Examiner, to Huffington Post and even Shape Magazine unfortunately the whole thing had been faked, kind of.
I mean researchers did perform the experiment exactly as they described, but they intentionally designed it to increase the likelihood of false positives: the sample size was incredibly small, just five people per treatment group, and for each person 18 different measurements were tracked including: weight, cholesterol, sodium, blood protein levels, sleep quality, well-being, and so on; so if weight loss didn't show a significant difference there were plenty of other factors that might have. So the headline could have been "chocolate lowers cholesterol" or "increases sleep quality" or. .
. something. The point is: a p-value is only really valid for a single measure once you're comparing a whole slew of variables the probability that at least one of them gives you a false positive goes way up, and this is known as "p-hacking".
Researchers can make a lot of decisions about their analysis that can decrease the p-value, for example let's say you analyze your data and you find it nearly reaches statistical significance, so you decide to collect just a few more data points to be sure then if the p-value drops below . 05 you stop collecting data, confident that these additional data points could only have made the result more significant if there were really a true relationship there, but numerical simulations show that relationships can cross the significance threshold by adding more data points even though a much larger sample would show that there really is no relationship. In fact, there are a great number of ways to increase the likelihood of significant results like: having two dependent variables, adding more observations, controlling for gender, or dropping one of three conditions combining all three of these strategies together increases the likelihood of a false-positive to over sixty percent, and that is using p less than .
05 Now if you think this is just a problem for psychology neuroscience or medicine, consider the pentaquark, an exotic particle made up of five quarks, as opposed to the regular three for protons or neutrons. Particle physics employs particularly stringent requirements for statistical significance referred to as 5-sigma or one chance in 3. 5 million of getting a false positive, but in 2002 a Japanese experiment found evidence for the Theta-plus pentaquark, and in the two years that followed 11 other independent experiments then looked for and found evidence of that same pentaquark with very high levels of statistical significance.
From July 2003 to May 2004 a theoretical paper on pentaquarks was published on average every other day, but alas, it was a false discovery for their experimental attempts to confirm that theta-plus pentaquark using greater statistical power failed to find any trace of its existence. The problem was those first scientists weren't blind to the data, they knew how the numbers were generated and what answer they expected to get, and the way the data was cut and analyzed, or p-hacked, produced the false finding. Now most scientists aren't p-hacking maliciously, there are legitimate decisions to be made about how to collect, analyze and report data, and these decisions impact on the statistical significance of results.
For example, 29 different research groups were given the same data and asked to determine if dark-skinned soccer players are more likely to be given red cards; using identical data some groups found there was no significant effect while others concluded dark-skinned players were three times as likely to receive a red card. The point is that data doesn't speak for itself, it must be interpreted. Looking at those results it seems that dark skinned players are more likely to get red carded but certainly not three times as likely; consensus helps in this case but for most results only one research group provides the analysis and therein lies the problem of incentives: scientists have huge incentives to publish papers, in fact their careers depend on it; as one scientist Brian Nosek puts it: "There is no cost to getting things wrong, the cost is not getting them published".
Journals are far more likely to publish results that reach statistical significance so if a method of data analysis results in a p-value less than . 05 then you're likely to go with that method, publication's also more likely if the result is novel and unexpected, this encourages researchers to investigate more and more unlikely hypotheses which further decreases the ratio of true to spurious relationships that are tested; now what about replication? Isn't science meant to self-correct by having other scientists replicate the findings of an initial discovery?
In theory yes but in practice it's more complicated, like take the precognition study from the start of this video: three researchers attempted to replicate one of those experiments, and what did they find? well, surprise surprise, the hit rate they obtained was not significantly different from chance. When they tried to publish their findings in the same journal as the original paper they were rejected.
The reason? The journal refuses to publish replication studies. So if you're a scientist the successful strategy is clear and don't even attempt replication studies because few journals will publish them, and there is a very good chance that your results won't be statistically significant any way in which case instead of being able to convince colleagues of the lack of reproducibility of an effect you will be accused of just not doing it right.
So a far better approach is to test novel and unexpected hypotheses and then p-hack your way to a statistically significant result. Now I don't want to be too cynical about this because over the past 10 years things have started changing for the better. Many scientists acknowledge the problems i've outlined and are starting to take steps to correct them: there are more large-scale replication studies undertaken in the last 10 years, plus there's a site, Retraction Watch, dedicated to publicizing papers that have been withdrawn, there are online repositories for unpublished negative results and there is a move towards submitting hypotheses and methods for peer review before conducting experiments with the guarantee that research will be published regardless of results so long as the procedure is followed.
This eliminates publication bias, promotes higher powered studies and lessens the incentive for p-hacking. The thing I find most striking about the reproducibility crisis in science is not the prevalence of incorrect information in published scientific journals after all getting to the truth we know is hard and mathematically not everything that is published can be correct. What gets me is the thought that even trying our best to figure out what's true, using our most sophisticated and rigorous mathematical tools: peer review, and the standards of practice, we still get it wrong so often; so how frequently do we delude ourselves when we're not using the scientific method?
As flawed as our science may be, it is far away more reliable than any other way of knowing that we have. This episode of veritasium was supported in part by these fine people on Patreon and by Audible. com, the leading provider of audiobooks online with hundreds of thousands of titles in all areas of literature including: fiction, nonfiction and periodicals, Audible offers a free 30-day trial to anyone who watches this channel, just go to audible.
com/veritasium so they know i sent you. A book i'd recommend is called "The Invention of Nature" by Andrea Wolf which is a biography of Alexander von Humboldt, an adventurer and naturalist who actually inspired Darwin to board the Beagle; you can download that book or any other of your choosing for a one month free trial at audible. com/veritasium so as always i want to thank Audible for supporting me and I really want to thank you for watching.
Related Videos

19:25
Clickbait is Unreasonably Effective
Veritasium
7,854,245 views

23:34
Why Democracy Is Mathematically Impossible
Veritasium
6,515,114 views

23:26
What The Longest Study On Happiness Reveals
Veritasium
5,492,417 views

27:40
The Biggest Misconception in Physics
Veritasium
5,846,024 views

20:01
Academia is BROKEN! - Harvard Fake Data Sc...
Pete Judo
2,019,582 views

3:22:50
Forest Cafe Jazz Music | Morning Tranquill...
Tranquill Jazz Melody
7,185,937 views

8:47
Top NIH scientist speaks out, says researc...
MSNBC
95,904 views

20:11
How the Trucking Industry Got So Terrible
Wendover Productions
569,321 views

15:13
How Magnetic Cooling Is Breaking All the R...
Undecided with Matt Ferrell
1,087,201 views

1:15:11
Veritasium: What Everyone Gets Wrong About...
Perimeter Institute for Theoretical Physics
1,215,807 views

29:35
The scandal that shook psychology to its core
Neuro Transmissions
376,984 views
24:52
The Most Useful Thing AI Has Ever Done
Veritasium
8,309,697 views

14:35
On These Questions, Smarter People Do Worse
Veritasium
5,327,383 views

31:13
Everything We Know About 'Oumuamua
Astrum
604,276 views

24:02
The Race to Harness Quantum Computing's Mi...
Bloomberg Originals
5,565,703 views

21:16
How the U.S. Found Saddam Hussein
neo
4,706,930 views

27:15
The Most Misunderstood Concept in Physics
Veritasium
20,950,943 views

31:33
The Oldest Unsolved Problem in Math
Veritasium
16,011,410 views

16:04
Lawrence: Trump, a 'humiliated clown' who ...
MSNBC
1,605,046 views

17:59
The Paradox of Being a Good Person - Georg...
Pursuit of Wonder
3,113,824 views